1. 什么是RDD
传统的MapReduce 虽然有自动容错,平衡负载和可扩展的优点,但是其最大的缺点是在迭代计算的时候,要进行大量的磁盘IO操作,而RDD正是解决这一缺点的抽象方法。RDD (Resilient Distributed Datasets) 即弹性分布式数据集,RDD是不可变的,如果运行RDD的节点故障,Driver会重建RDD并指派到新的节点上,在计算过程中,数据一直都是静态的。在RDD算子计算过程中会尽可能的将数据存在内存当中,如果数据增长超过限制会将数据写到磁盘,绝大多数的RDD的处理会在内存中进行,这也是Spark能够高速计算的原因之一。RDD是强类型的。
- Resilient(弹性):
1.当计算过程中内存不足时可以刷写到磁盘等外存上,可与外部存储做灵活的数据交换;
2.RDD使用了一种“血统”的容错机制,在结构更新和丢失后可随时根据血统进行数据模型的重建
Distributed(分布式):
数据可以分布在多台机器上,并进行并行计算Datasets(数据集):
一组只读的、可分区的分布式数据集。集合内包含了多个分区。分区依照特定规则将具有相同属性的数据记录放在一起,每个分区相当于一个数据集片段。
2. RDD 内部结构
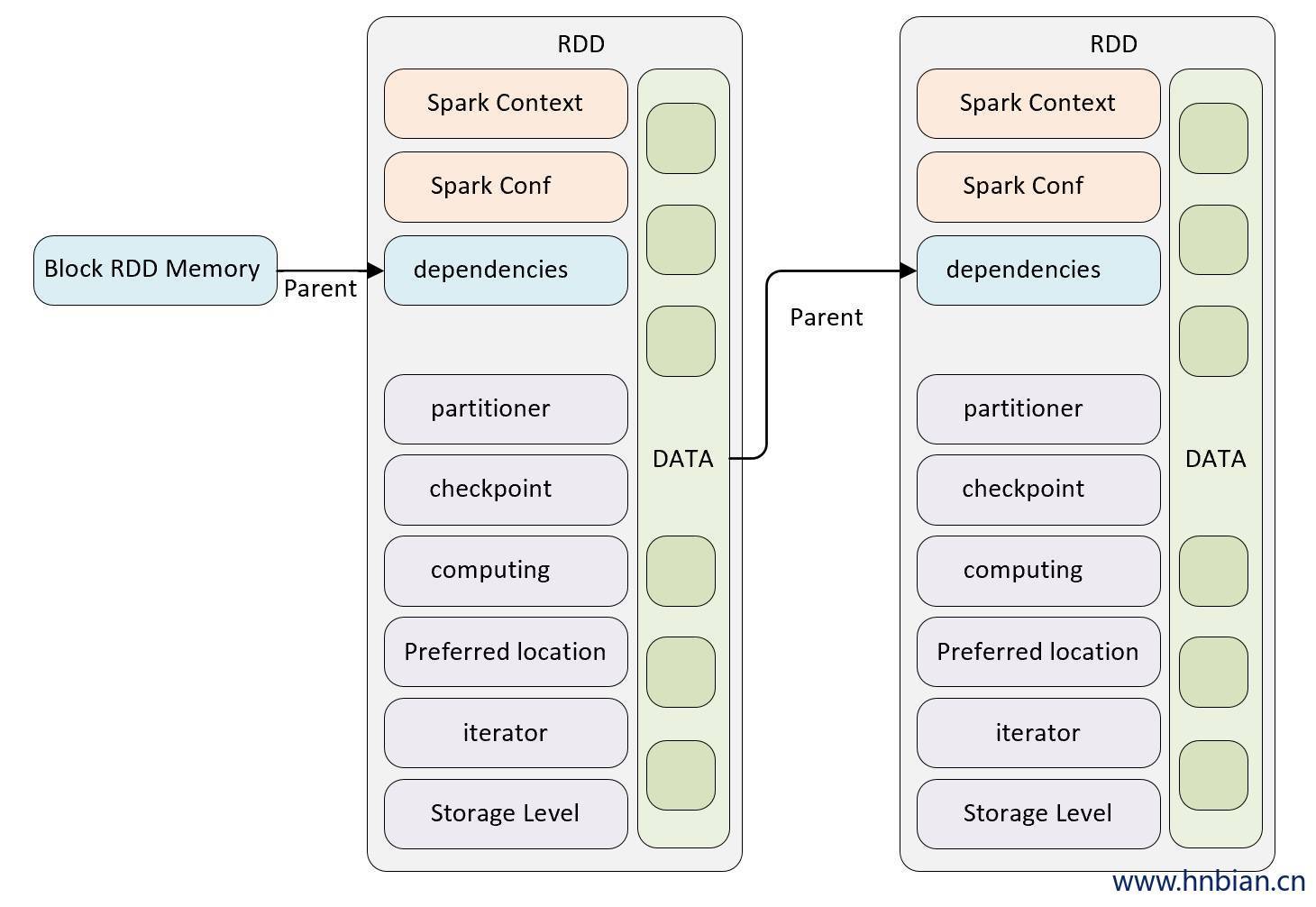
RDD是一个只读的,有属性的数据集。它的属性用来描述当前数据集的状态,数据集由数据的分区(partition)组成,并由块(block)映射成真实数据。
RDD的主要属性可分为3类:
- 与其他RDD的关系(容错)(parents,dependencies);
- 数据(partitioner,checkpoint,storage level,iterator 等);
- RDD自身属性(SparkContext,SparkConf),
3. RDD 的自身属性
3.1 SparkContext
SparkContext是Spark job 的入口,由Driver 创建在Client端,包括集群链接、RDD ID 、累加器、广播变量等信息。
3.2 SparkConf
SparkConf是参数配置信息,包括:
- Spark api:控制大部分的应用程序参数
- 环境变量:配置IP地址、端口等信息
- 日志配置:通过log4g.properties 配置。
4.RDD 数据相关属性
4.1 分区(Partition)
RDD 内部的数据集在逻辑上和物理上被划分成多个小子集合,这样的每一个子集合我们将其称为一个分区(Partition),分区的个数会决定并行计算的粒度,而每一个分区数值的计算都是在一个单独的任务中进行的,因此并行任务的个数也是有RDD的分区个数决定的。但事实上RDD只是数据集的抽象,分区内部并不会存储具体的数据。Partition类内包含一个index成员,表示该分区在RDD内的编号,通过RDD编号+分区编号可以确定该分区对应的唯一块编号,再利用底层数据存储层提供的接口就能从存储介质(如:HDFS、Memory)中提取出分区对应的数据。
RDD的分区方式主要包含两种:Hash Partitioner 和 Range Partitioner,这两种分区都是针对 key-value类型的数据,如果不是 key-value 类型则分区函数为None。
- Hash Partitioner:以key作为分区条件的散列分布,分区数据不连续,极端情况也可能散列到少数几个分区上导致数据不均等;
- Range Partitioner:按照key的平均分布,分区数据连续,大小也相对均匀等。
4.2 首选位置(Preferred Location)
Preferred Location 是一个列表,用于存储每个Partition的优先位置。对于每个HDFS文件来说,这个列表保存的是每个partition所在的位置,也就是该文件的划分点。
4.3 持久化
4.3.1 存储级别(Storage Level)
Storage Level 是RDD持久化的存储级别,RDD持久化可以调用两个方法:cache 和 persist
- persist:可以自由设置存储级别,默认是持久化到内存。
- cache:将RDD持久化到内存,cache内部实际上是调用了persist方法,由于没有开放存储级别的参数,所以是直接持久化到内存。
| 存储级别 | 说明 |
|---|---|
| MEMORY_ONLY | 将RDD作为非序列化的Java对象存储在JVM中。如果RDD不适合存在内存中,一些分区将不会被缓存,而每次需要这些分区时都需要重新计算它们,这是系统默认的存储级别 |
| MEMORY_ONLY_SER | 跟MEMORY_ONLY类似但在持久化时,会将RDD作为序列化的Java对象存储(每个分区有一个byte数组)。这种方式比非序列化方式更节省空间,特别是用到快速序列化工具时,但是会更消费CPU资源——密集的 |
| MEMORY_AND_DISK | 将RDD作为非序列化的Java对象存储在JVM中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 |
| MEMORY_AND_DISK_SER | 将RDD作为序列化的Java对象存储在JVM中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 |
| DISK_ONLY | 仅将RDD分区保存在磁盘中 |
| DISK_ONLY_2 MEMORY_AND_DISK_2 |
和上面的存储级别类似,区别在于复制每个分区到集群的两个节点上面,就是要保存两个副本。 |
| OFF_HEAP (experimental) |
以序列化的格式将RDD存储到tachyon中。相对于MEMORY_ONLY_SER,OFF_HEAP减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中有更强的吸引力。 |
4.3.2 存储级别选择
上面表格是Storage Level 各级分布,那么如何选择一种最适合的持久化策略呢?
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够大到可以绰绰有余的存放下整个RDD的所有数据。因为不进行序列化与反序列化的操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据,不需要从磁盘文件中读取,性能也很高;而且不需要复制一份副本,并远程传送到其它节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM 的 OOM 内存溢出的异常。
如果使用MEMORY_ONLY级别发生内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销主要就是序列化与反序列化的开销,但是后续算子可以基于内存进行操作,因此性能总体还是比较高的。但可能发生OOM内存溢出异常。
如果纯内存级别都无法使用,那么建议使用MEMORY_AND_DISK_SER 策略,而不是MEMORY_AND_DISK策略, 因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下,序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY 和后缀_2的级别,因为完全基于磁盘文件进行数据的读写,会导致性能急剧下降。后缀为_2的级别,必须将所有数据都复制一份副本发送到其他节点上,数据复制以及网络传输会导致较大的性能开销
4.3.2 删除持久化数据
Spark会自动监视每个节点的缓存使用情况,并以最近最少使用(LRU)方式丢弃旧的数据分区。如果您想手动删除RDD,而不是等待它脱离缓存,请使用该 RDD.unpersist() 方法。
4.4 CheckPoint
CheckPoint 是Spark提供的一种缓存机制,当需要计算依赖链比较长又想避免重复计算之前的RDD时,可以对RDD做CheckPoint处理,检查RDD是否需要被物化或计算,并将结果持久化到磁盘或者HDFS内。CheckPoint会把当前RDD保存到一个目录,要出发action 操作时它才会执行。在CheckPoint 之前应该先做持久化(persist 或者 cache)操作, 否则要重新计算一遍。若某个RDD成功执行CheckPoint,它前面所有的依赖链会被销毁。
CheckPoint与cache相比较:
cache 缓存数据有executor管理,若executor消失,那么cache的数据将会被清除,RDD需要重新计算;
CheckPoint将数据保存到磁盘或HDFS内,job可以从CheckPoint点还原之前计算的内容并执行下面的计算。
CheckPoint与DISK_ONLY 存储级别的区别
DISK_ONLY 在使用RDD第一次被计算得到时将RDD保存到磁盘上,等到作业结束时保存到磁盘上的RDD就会被清除。
CheckPoint将RDD持久化到HDFS或本地文件夹如果不手动remove掉,数据会一直存在的。
4.5 Compute
Compute 函数实现方式就是向上递归,【获取父RDD分区并进行计算】,直到遇到检查点RDD获取缓存的RDD
4.6 Iterator
Iterator 用来查找当前RDD Partition 与父RDD partition的血缘关系,并通过Storage Level 确定迭代位置,直到确定真实数据的位置。它的实现流程如下:
若标记了有缓存,则缓存,如果取不到则进行computeOrReadCheckPoint(计算或读检查点)。然后再存入缓存,以备后续使用。
若未标记有缓存,则直接进行computeOrReadCheckPoint 这个过程也有两个判断:
- 如果有做过CheckPoint则可以读取到检查点数据返回
- 如果没有则调用该RDD的实现类的compute函数计算
5. RDD 容错机制
一个作业从开始到结束的计算过程中产生了很多个RDD,RDD之间是彼此相互依赖的,我们把这种父子依赖关系称之为“血统”。
万一某个RDD的某些partition挂掉了,可以通过其他RDD并行计算迅速恢复出来。RDD支持粗粒度的变换,即只记录单个块(分区)上执行的单个操作,然后将创建某个RDD的变换序列(lineage)存储下来。
变换序列是指每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息。
因此RDD的容错机制又称”血统”容错,要实现这种“血统”容错机制,最大的难题就是如何表达父RDD 与子RDD之间的依赖关系。

父RDD的每个分区最多只能被一个子RDD分区使用时,称为窄依赖(narrow dependency)
若父RDD的每个分区被子RDD的多个分区使用时,称为宽依赖(wide dependency)
简单来讲,窄依赖就是父子RDD分区间是一对一的关系,而宽依赖父子RDD分区间是一对多的关系。从失败恢复来看,窄依赖的失败恢复起来更高效,因为它只需要找个父RDD的一个对应分区即可,而且可以在不同节点上并行计算做恢复,而宽依赖涉及到的父RDD的多个分区,需要得到所有依赖的父RDD分区的shuffle结果,恢复起来相对复杂些。
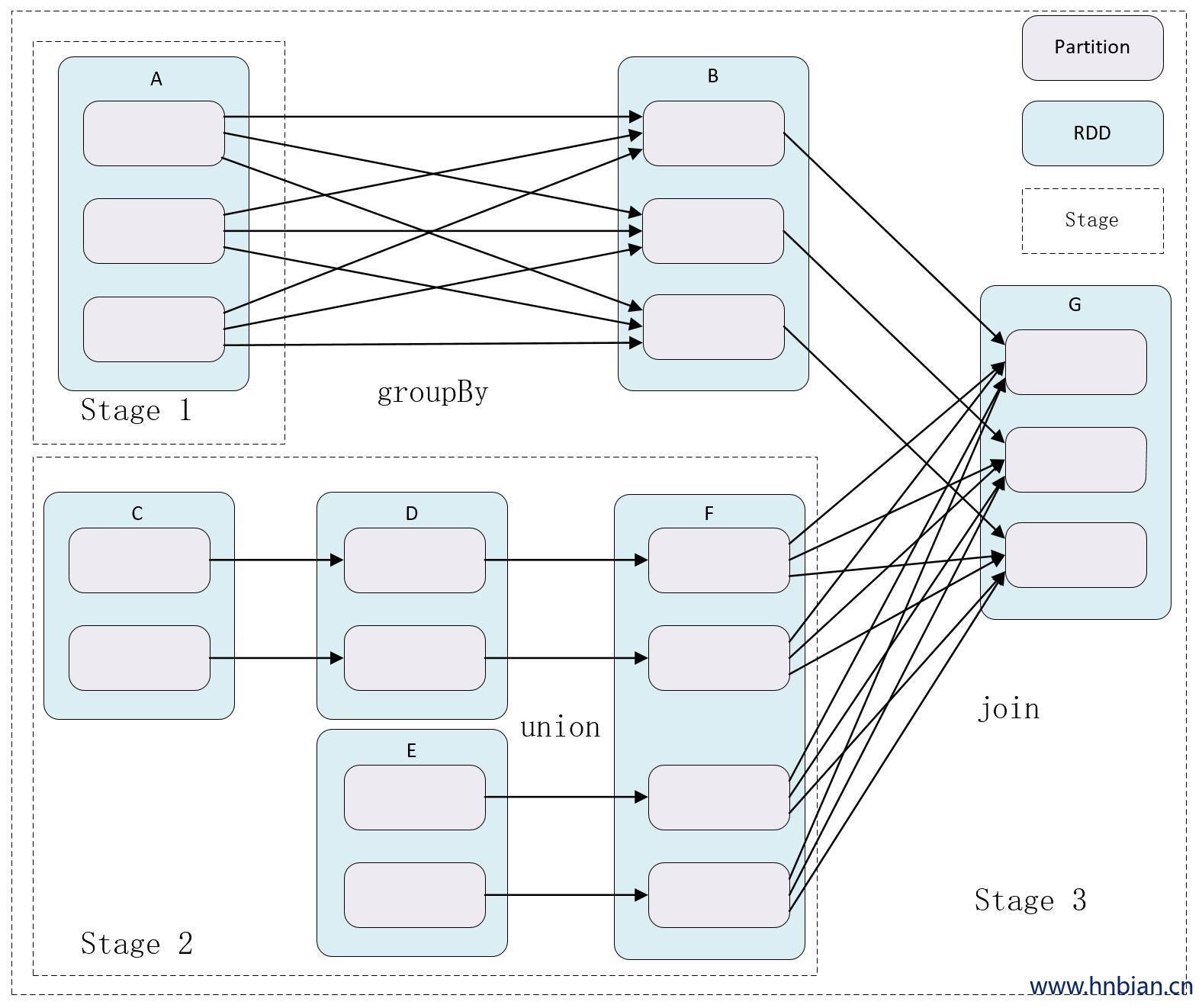
根据RDD之前的宽窄依赖关系引申出Stage 的概念,Stage是由一组RDD组成的执行计划。如果RDD的衍生关系都是窄依赖,则可放在同一个Stage中运行,若RDD的依赖关系为宽依赖,则要划分到不同的Stage。这样Spark在执行作业时,会按照Stage的划分,生成一个最优、完整的执行计划。
5.1 依赖类层级
Dependency 依赖的基类 (抽象类)
|→ shuffleDependency 宽依赖
|→ Narrowdependency 窄依赖
|––→ RangeDependency:表示父级和子级RDD中分区范围之间的一对一依赖关系。
|––→ OneToOneDependency:表示父RDD和子RDD的分区之间的一对一依赖关系
|––→ PruneDependency:表示PartitionPruningRdd与其父类之间的依赖关系, 在这种情况下, 子RDD包含了父类的分区子集
6. RDD的创建方式
RDD的创建方式有四种:
- 使用程序中的集合创建RDD,RDD的数据源是程序中的集合,通过parallelize 或者makeRdd将集合转化为RDD
scala> val num = Array(1,2,3,4,5)
num: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd1 = sc.parallelize(num)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
scala> val rdd2 = sc.makeRDD(num)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:26- 使用本地文件或者HDFS创建RDD,RDD的数据源是本地文件系统或者HDFS数据,使用textFile方法创建RDD。
scala> val rdd3 = sc.textFile("hdfs:///test/word.txt")
rdd3: org.apache.spark.rdd.RDD[String] = hdfs:///test/word.txt MapPartitionsRDD[3] at textFile at
scala> val rdd4 = sc.textFile(“file:///root/derby.log”) //使用本地文件创建
rdd4: org.apache.spark.rdd.RDD[String] = file:///root/derby.log MapPartitionsRDD[9] at textFile at
3. 使用数据流创建RDD,使用Spark Streaming的相关类,接收实时的输入数据流创建RDD(数据来源可以是kafka、flume等)
```scala
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream(“localhost”, 9999)
val words = lines.flatMap(_.split(“ ”))- 使用其他方式创建 RDD,从其他数据库上创建 RDD,例如 Hbase、MySQL 等。
val sqlContext = new SQLContext(sc)
val url = "jdbc:mysql://ip:port/xxxx"
val prop = new Properties()
val df = sqlContext.read.jdbc(url, “play_time”, prop)7. RDD的分区机制
RDD的分区机制有两个关键点:
一个是关键参数,即Spark的默认并发数 Spark.default.parallelism;
另外一个是关键原则,RDD分区尽可能使得分区的个数等于集群核心(core)数量.
当配置文件 spark-default.conf 中显式配置了spark.default.parallelism,那么 spark.default.parallelism=配置的值,否则按照下面规则进行取值:
- 本地模式(不启动executor,由SparkSubmit 进程生成指定数量的线程数来并发)
spark-shell spark.default.parallelism = 1
spark-shell --master local[N] spark.default.parallelism = N (使用N个核 core)
spark-shell --master local spark.default.parallelism = 12.伪集群模式(x为本机上启动的executor数;y为每个executor使用的core 数;z为每个executor使用的内存)
spark-shell --master local-cluster[x,y,z] spark.default.parallelism = x * y3.Yarn、standalone 等模式
spark.default.parallelism = max (所有 executor 使用的core 总数 * 2)7.1 RDD 分区数量推算
spark.context 会生成两个参数,由spark.default.parallelism 推导出这两个参数的值:
sc.defaultParallelism = spark.default.parallelism
sc.defaultMinpartitions = min(spark.default.parallelism,2)
当sc.defaultParallelism 和 sc.defaultMinPartitions 确认后, 就可以推算RDD的分区数了。
parallelize 方式生成RDD
val rdd = sc.parallelize(1 to 10)
如果使用parallelize方法没有指定分区数,RDD的分区数 = sc.defaultParallelism
textFile方法生成RDD
val rdd = sc.textFile(“path/file”)
这种机制分为两种情况:
1.从本地文件生成的RDD,如果没有指定分区数,则默认分区数规则为
rdd 的分区数 = max(本地文件分片数,sc.defaultMinPartitions)
2.从HDFS 生成的RDD,如果没有指定分区数,则默认分区数规则为:
RDD的分区数 = max(HDFS文件的块数,sc.defauleMinPartitions)
8. RDD的常规操作(算子)
8.1 RDD算子的分类
从大方向来说,RDD算子分为 转换(Transformation) 和动作(Action)两类:
Transformation算子并不会触发提交作业,Transformation算子具有lazy的特性,它的操作是延迟计算的,也就是说从RDD转换生成另一个RDD的操作并不是马上执行的,需要等到有Action操作的时候才会真正的触发运算。
Action算子会触发SparkContext提交Job作业,它会根据DAG图真正执行计算,并将数据输出Spark系统。
从小的方向来说,RDD算子还可以分为以下三类:
- 处理value数据的Transformation算子的转换算子针对处理数据是value类型的数据
| 功能 | 算子 |
|---|---|
| 输入分区与输出分区一对一型 | map、flatMap、mapPartitions、glom |
| 输入分区与输出分区多对一型 | cartesian |
| 输入分区与输出分区多对多型 | grouBy |
| 输出分区为输入分区子集型 | filter、distinct、subtract、sample、takeSample |
| 持久化 | cache、persist |
- Key-Value数据类型的Transformation算子,这是针对数据项是Key-Value类型的数据对
| 功能 | 算子 |
|---|---|
| 输入分区与输出分区一对一 | mapValues |
| 单个RDD聚集 | combineByKey、reduceByKey、partitionBy |
| 两个RDD聚集 | Cogroup |
| 连接 | join、leftOutJoin、rightOutJoin |
- Action算子,这类算子会触发SparkContext提交Job作业。
| 功能 | 算子 |
|---|---|
| 无输出 | foreach |
| 保存文件 | saveAsTextFile、saveAsObjectFile |
| Scala集合和数据类型 | collect、collectAsMap、reduceByKeyLocally、lookup、count、top、reduce、fold、aggregate |
8.2 RDD算子的计算流程(WordCount)
以wordcount为例说明多个算子的计算流程
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val filePath = "D:\\Documents\\WordCount.txt"
//Life is a journey not the destination but the scenery along the should be and the mood at the view
val conf = new SparkConf().setAppName("WordCount Application")
//设置master local[4] 指定本地模式开启模拟worker线程数
conf.setMaster("local[4]")
//创建sparkContext文件
val sc = new SparkContext(conf)
val rdd1 = sc.textFile(filePath)
.flatMap(words=>{words.split(" ")})
.map(words=>(words,1))
.reduceByKey((a,b)=> a + b)
rdd1.foreach(words=>{
println(words)
})
}
}



![13.[Java 面向对象] 多态](https://images.hnbian.cn/Fof-p2iJ5oEvuNECBIVcpbpFMsTy)