1. 数据存储
分布式数据存储基本原理相对简单,实现比较容易,很多数据库中间件也可以做到基本的分布式数据存储。Greenplum 在这方面不单单做到了基本的分布式数据存储,还提供了很多更高级灵活的特性,譬如多级分区、多态存储。Greenplum 6 进一步增强了这一领域,实现了一致性哈希和复制表,并允许用户根据应用干预数据分布方法。
如下图所示,用户看到的是一个逻辑数据库,每个数据库有系统表(例如 pg_catalog 下面的 pg_class, pg_proc 等)和用户表(下例中为 sales 表和 customers 表)。在物理层面,它有很多个独立的数据库组成。每个数据库都有它自己的一份系统表和用户表。

master 数据库仅仅包含元数据而不保存用户数据。master 上仍然有用户数据表,这些用户数据表都是空表,没有数据。优化器需要使用这些空表进行查询优化和计划生成。segment 数据库上绝大多数系统表(除了少数表,例如统计信息相关表)和 master 上的系统表内容一样,每个 segment 都保存用户数据表的一部分。
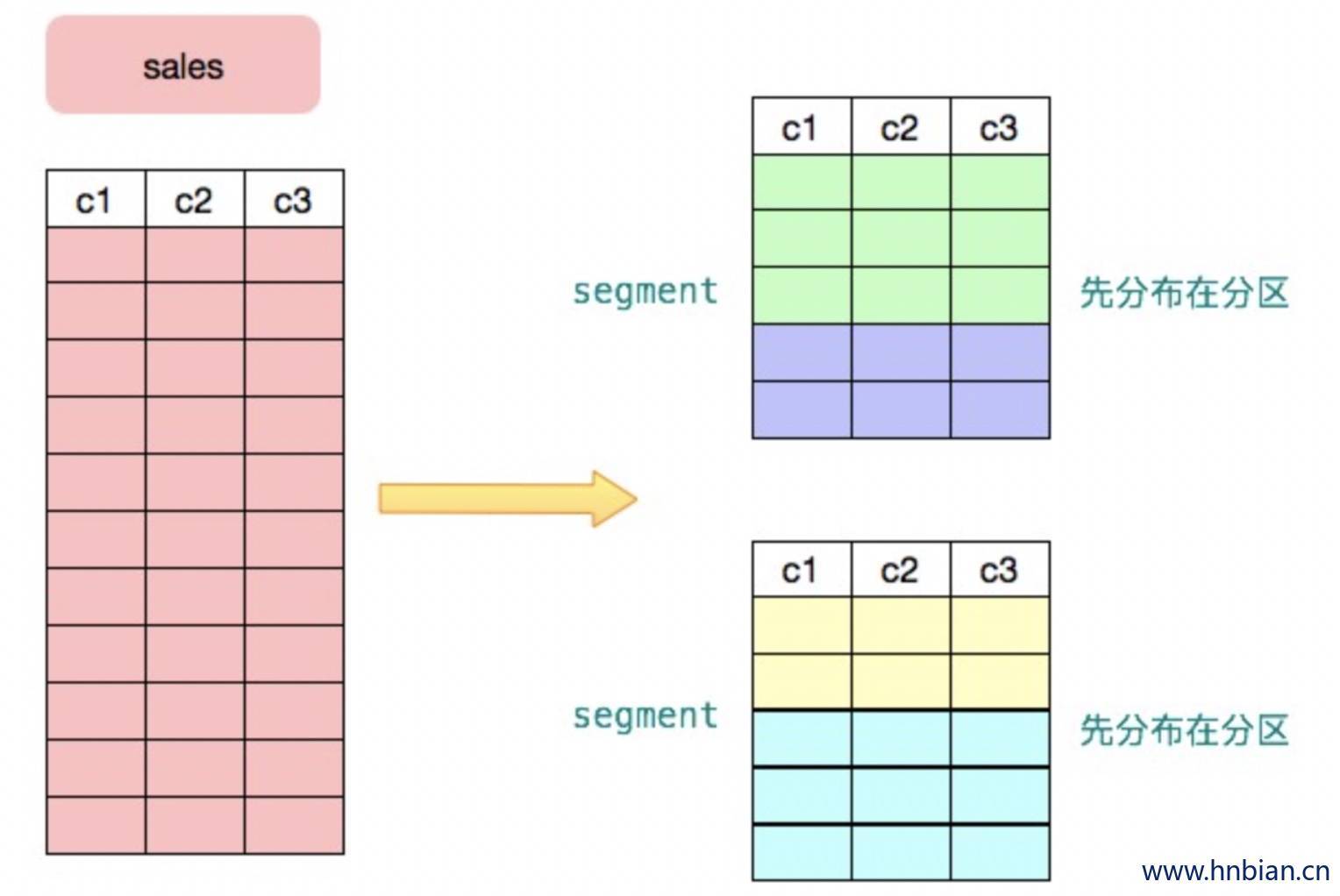
在 Greenplum 中,用户数据按照某种策略分散到不同节点的不同 segment 实例中。每个实例都有自己独立的数据目录,以磁盘文件的方式保存用户数据。使用标准的 INSERT SQL 语句可以将数据自动按照用户定义的策略分布到合适的节点,然而 INSERT 性能较低,仅适合插入少量数据。Greenplum 提供了专门的并行化数据加载工具以实现高效数据导入,详情可以参考 gpfdist 和 gpload 的官方文档。此外 Greenplum 还支持并行 COPY,如果数据已经保存在每个 segment 上,这是最快的数据加载方法。下图形象的展示了用户的 sales 表数据被分布到不同的 segment 实例上。
2. 分区表
分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面。Greenplum中分区表的原理和PostgreSQL一样,都是通过表继承和约束实现的。
Greenplum官方给出的分区表示例如下:
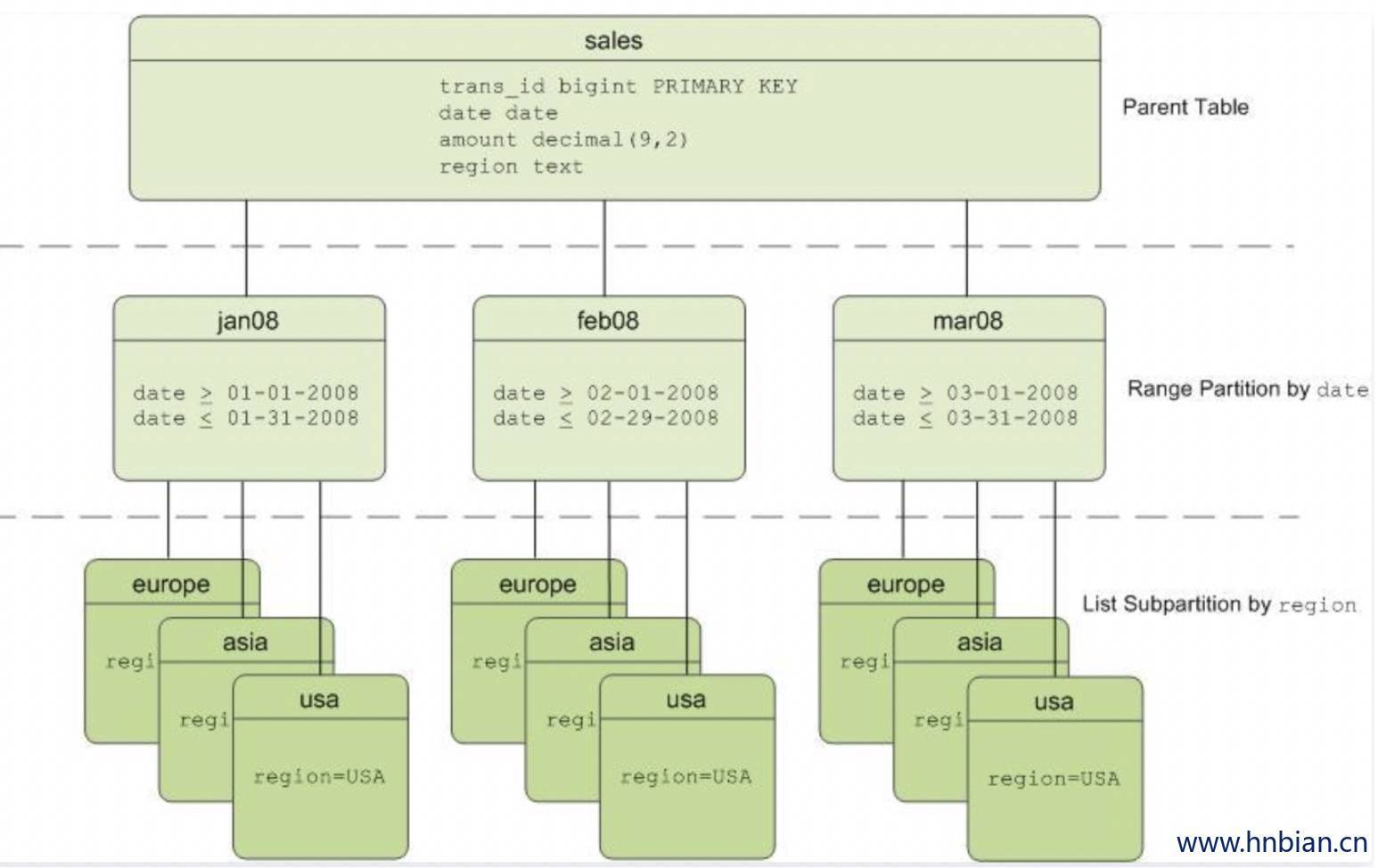
2.1 分区与分布的区别
分布:DISTRIBUTED
分区:PARTITION
数据分布是在物理上拆分表数据,将数据打散到各个节点,使数据可以并行计算,这在Greenplum中是必须的。
表分区是在逻辑上拆分大表的数据提高查询性能,也有利于数据生命周期的管理,这在Greenplum中是可选的。
无论是分区表还是非分区表,在Greenplum中,数据都是分散到各个节点上的。分区不会影响数据在各个节点上的分布情况。
2.2 范围分区
根据某个列的时间范围或者数值范围对数据分区。譬如以下 SQL 将创建一个分区表,该表按天分区,从 2019-01-01 到 2020-01-01 把全部一年的数据按天分成了 366 个分区
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2019-01-01') INCLUSIVE
END (date '2020-01-01') EXCLUSIVE
EVERY (INTERVAL '1 day') );
2.3 列表分区
按照某个列的数据值列表,将数据分不到不同的分区。譬如以下 SQL 根据性别创建一个分区表,该表有三个分区:一个分区存储女士数据,一个分区存储男士数据,对于其他值譬如 NULL,则存储在单独 other 分区。
CREATE TABLE rank (id int, rank int, year int, gender char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
( PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION other );
下图展示了用户的 sales 表首先被分布到两个节点,然后每个节点又按照某个标准进行了分区。分区的主要目的是实现分区裁剪以通过降低数据访问量来提高性能。分区裁剪指根据查询条件,优化器自动把不需要访问的分区过滤掉,以降低查询执行时的数据扫描量。PostgreSQL 支持静态条件分区裁剪,Greenplum 通过 ORCA 优化器实现了动态分区裁剪。动态分区裁剪可以提升十几倍至数百倍性能。
3.2 存储格式
3.2.1 存储格式介绍
Greenplum(以下简称GP)有2种存储格式,Heap表和AO表(AORO表,AOCO表) 。
Heap表:这种存储格式是从PostgreSQL继承而来的,目前是GP默认的表存储格式,只支持行存储。
AO表: AO表最初设计是只支持append的 (就是只能insert), 因此全称是Append-Only,在4.3之后进行了优化,目前已经可以update和delete了,全称也改为Append-Optimized。AO支持行存储(AORO)和列存储(AOCO)。
3.2.2 Heap表
Heap表是从PostgreSQL继承而来,使用MVCC来实现一致性。如果你在创建表的时候没有指定任何存储格式,那么GP就会使用Heap表。
Heap表支持分区表,只支持行存,不支持列存和压缩。需要注意的是在处理update和delete的时候,Heap表并没有真正删除数据,而只是依靠version信息屏蔽老的数据,因此如果你的表有大量的update或者delete,表占用的物理空间会不断增大,这个时候需要依靠vacuum来清理老数据。
Heap表不支持逻辑增量备份,因此如果要对Heap表做快照,每次都需要导出全量数据。
建表语句
CREATE TABLE heap(
a int,
b varchar(32)
) DISTRIBUTED BY (a);
最佳实践:
如果该表是一张小表,比如数仓中的维度表,或者数据量在百万以下,推荐使用Heap表。
如果该表的使用场景是OLTP的,比如有较多的update和delete,查询多是带索引的点查询等,推荐使用Heap表。
3.2.3 AO表
AO表是GP特有的,设计的目的就是为了数仓中大型的事实表。AO表支持行存和列存,并且也支持对数据进行压缩。
AO表无论是在表的逻辑结构还是物理结构上,都与Heap表有很大的不同。比如上文所述Heap表使用MVCC控制update和delete之后数据的可见性,而AO表则使用一个附加的bitmap表来实现,这个表的的内容就是表示AO表中哪些数据是可见的。
对于有大量update和delete的AO表,同样需要vacuum进行维护,不过在AO表中,vacuum需要对bitmap进行重置并压缩物理文件,因此通常比Heap的vacuum要慢。
3.2.4 AORO表
AORO就是行存的AO表,同时行存也是AO表的默认存储方式。
AORO支持表级别的压缩,不支持列级别的压缩。
3.2.4.1 建表语句
CREATE TABLE aoro(
a int,
b int,
c varchar(32),
d varchar(32)
)
WITH (appendonly=true, orientation=row, compresstype=zlib, compresslevel=4)
DISTRIBUTED BY (a)
重点是with后的appendonly=true,由于AO表默认是行存,因此orientation=row也可以不要,后面的compresstype=zlib, compresslevel=4都是压缩相关选项。
3.2.4.2 压缩选项
compresstype :压缩格式,开源版本的AORO表只支持zlib。
compresslevel :压缩级别,从1-9,简单说来,级别越低(1最低),压缩比越低,但是压缩与解压消耗的cpu资源就越少。默认压缩级别是1。
3.2.4.3 最佳实践
AO表主要是针对大表,比如数仓中的事实表。
AO表支持逻辑增量备份,对于比较大的表,如果需要定期做快照,建议使用AO表,否则每次都要导出全量数据。
如果该表是大表,使用场景偏OLTP并且update和delete频率不高,可以考虑使用AORO表。
如果该表是大表,并且查询通常都需要扫描大多数列比如查询明细(最典型的就是SELECT * FROM),可以考虑使用AORO表。
在设置压缩级别的时候,通常对于Snova用户,设置到4或者5是比较折中的一个选择。
3.2.5 AOCO表
AOCO表就是列存的AO表。
AOCO不仅支持表级别的压缩,同时也支持列级别的压缩。
3.2.5.1 建表语句
CREATE TABLE aoco(
a int ENCODING (compresstype=zlib, compresslevel=5),
b int ENCODING (compresstype=none),
c varchar(32) ENCODING (compresstype=RLE_TYPE, blocksize=32768),
d varchar(32),
fdate date
)
WITH (appendonly=true, orientation=column, compresstype=zlib, compresslevel=6, blocksize=65536)
DISTRIBUTED BY (a)
PARTITION BY RANGE(fdate)
(
PARTITION pn START ('2018-11-01'::date) END ('2018-11-10'::date) EVERY ('1 day'::interval),
DEFAULT PARTITION pdefault
);3.2.5.2 压缩选项
compresstype:支持2种压缩格式,zlib和RLE_TYPE,其中RLE_TYPE(Run-length Encoding)对于有较多重复值的列压缩比很高,因为它会将多个重复值存储为一个值,从而大大降低存储量,比如日期,性别,年龄等字段。
compresslevel:compresstype如果是zlib,compresslevel在1-9,compresstype如果是RLE_TYPE,compresslevel在1-4。
列压缩与表压缩:AOCO表除了支持表级别的压缩外,还支持列级别的压缩,列级别的压缩配置会覆盖表级别的压缩配置,比如上述语法中4个字段,每个字段都采用了不用的压缩方式,d列没有定义,则会默认使用表级别的压缩方式。
分区压缩:在使用分区表的时候,每个分区表也可以设置不同的压缩配置,这个常用于对数据进行冷热分离,比如对于非常老的数据,由于访问频率较低,可以考虑采用较大的压缩比,减少存储量。
3.2.5.3 BLOCKSIZE
表的存储块大小,通常表数据对应的物理文件就是按blocksize的粒度增加,也就是初始就是blocksize大,并且保持blocksize的倍数。在AOCO表中,每一列也可以设置自己的blocksize,列的配置会覆盖表的配置。
blocksize大小在8192和2097152之间,必须是8192的倍数,默认是32768。
3.2.5.4 物理文件
AOCO表之所以能够按照列来设置压缩等参数,本质原因在于AOCO表中每一列的数据都会单独存储在一个文件中。因此不同文件之间可以按不同的参数进行存储,互不影响。
对于AOCO表,如果使用了分区,那么对于每一个分区的每一列都会有一个文件,如果一个表的分区很多,又是一张大宽表,那么产生的文件就会很多,也会对性能有一些影响。
3.2.5.5 最佳实践
AOCO表通常用于数仓中的核心事实表,这种表字段多,数据量大,主要是用于OLAP场景,也就是查询的过程不会SELECT * FROM,而是对其中部分字段进行读取和聚合。
由于AOCO表一般用于大表,因此经常搭配压缩和分区,以减少表的实际存储量来提升性能。
一般情况下,压缩格式选择zlib,压缩级别可以采用折中的4或者5,但是对于有大量重复值的字段,记得要采用RLE_TYPE压缩格式。
blocksize不要设置过大,特别是对于分区表,GP对于每个分区的每个字段都会维护一个buffer,blocksize过大,会导致消耗的内存过大,通常就采用默认值32768即可。
3.2.6 外部表
外部表的数据存储在外部(数据不被 Greenplum 管理),Greenplum 中只有外部表的元数据信息。Greenplum 支持很多外部数据源譬如 S3、HDFS、文件、Gemfire、各种关系数据库等和多种数据格式譬如 Text、CSV、Avro、Parquet 等。
3.2.7 修改表结构
Heap、AORO和AOCO这3种表在修改表结构时表现是不一样的,对于不同的表类型,同样的修改语法耗时可能会差异很多,主要原因在于对于有些修改操作会导致表重写,而表重写的时间就取决于表本身的数据量。
以下列出了不同的表结构,在不同的ALTER语法下的行为,其中YES代表需要重写表,NO代表不需要重写表。
| 操作 | Heap | AORO | AOCO |
|---|---|---|---|
| ADD COLUMN | NO | YES | NO |
| DROP COLUMN | NO | NO | NO |
| ALTER COLUMN TYPE | YES | YES | YES |
| ADD COLUMN DEFAULT NULL | YES | YES | NO |
| ADD COLUMN DEFAULT VALUE | YES | YES | NO |
可以看出AOCO表由于每个列都是单独一个文件,因此在修改列结构时影响最小,这也是AOCO表的一个优势。
3.2.8 对比测试
3.2.8.1 各类型表占用空间比较
选取Heap,AORO,AOCO三种表,分别采用压缩和不压缩2种方式(Heap表不支持压缩,AO表压缩采用zlib格式,压缩级别设置为6),插入5亿条随机数据,然后使用
select pg_size_pretty(pg_relation_size('{tablename}'));
查看表所占大小,结果如下:
图表待补充
可以看出Heap表占用空间更大,即使AO表不采用压缩。AOCO表由于是按列进行存储,所以相比行存的AORO表压缩比更大。当然这三者的差距取决于数据的实际情况,一般生产环境中Heap表不会和AO表有如此大的差距。
3.2.8.2 各级别压缩率比较
使用AOCO表,zlib压缩格式,选取不同的压缩级别,比较数据写入时间和表所占大小,由于zlib支持9个级别,这里选取1,6,9 三个级别进行比较,体现出趋势即可,结果如下:
图表待补充
实际生产环境中不同压缩级别的数据,压缩比的差距可能会更大。但可以看出,越高的压缩级别,在插入的时候越耗时,其它SQL,类似SELECT,UPDATE等也都是一样。
3.3 分布策略
数据分布是任何 MPP 数据库的基础,也是 MPP 数据库是否高效的关键之一。通过把海量数据分散到多个节点上,一方面大大降低了单个节点处理的数据量,另一方面也为处理并行化奠定了基础,两者结合起来可以极大的提高整个系统的性能。譬如在一百个节点的集群上,每个节点仅保存总数据量的百分之一,一百个节点同时并行处理,性能会是单个配置更强节点的几十倍。如果数据分布不均匀出现数据倾斜,受短板效应制约,整个系统的性能将会和最慢的节点相同。因而数据分布是否合理对 Greenplum 整体性能影响很大。
Greenplum中每个表都需要有一个分布键,如果你建表的时候没有显示使用语法DISTRIBUTED BY (column) 指定一个分布键,系统也会默认为你指定一个。分布目的是把数据打散到每个节点,打散的规则是hash或者random。这样在计算时可以充分利用每个节点的资源进行并行计算。
3.3.1 哈希( Hash )分布
哈希分布是 Greenlum 最常用的数据分布方式。根据预定义的分布键计算用户数据的哈希值,然后把哈希值映射到某个 segment 上。 分布键可以包含多个字段。分布键选择是否恰当是 Greenplum 能否发挥性能的主要因素。好的分布键将数据均匀分布到各个 segment 上,避免数据倾斜。
Greenplum 计算分布键哈希值的代码在 cdbhash.c 中。结构体 CdbHash 是处理分布键哈希的主要数据结构。 计算分布键哈希值的逻辑为:
使用 makeCdbHash(int segnum) 创建一个 CdbHash 结构体
然后对每个 tuple 执行下面操作,计算该 tuple 对应的哈希值,并确定该 tuple 应该分布到哪个 segment 上:
1) cdbhashinit():执行初始化操作
2) cdbhash(), 这个函数会调用 hashDatum() 针对不同类型做不同的预处理,最后 addToCdbHash() 将处理后的列值添加到哈希计算中
3) cdbhashreduce() 映射哈希值到某个 segment
3.3.2 随机( Random )分布
使用 Random 分布方式,表中的数据将均匀地打散到各个子节点上,并且随着数据地进入顺序循环 地打散到各个子节点上,表上相同的值并不一定颁布在同一个节点上,官方认为选择 Hash 分区方式在性能上占有优势。
create table t1 (id int) DISTRIBUTED RANDOMLY;
如果不能确定一张表的哈希分布键或者不存在合理的避免数据倾斜的分布键,则可以使用随机分布。随机分布会采用循环的方式将一次插入的数据存储到不同的节点上。随机性只在单个 SQL 中有效,不考虑跨 SQL 的情况。譬如如果每次插入一行数据到随机分布表中,最终的数据会全部保存在第一个节点上。
有些工具使用随机分布实现数据管理,譬如扩容工具 gpexpand 在增加节点后需要对数据进行重分布。在初始化的时候,gpexpand 会把所有表都标记为随机分布,然后执行重新分布操作,这样重分布操作不影响业务的正常运行。(Greenplum 6 重新设计了 gpexpand,不再需要修改分布策略为随机分布)
3.3.3 复制表(Replicated Table)
Greenplum 6 支持一种新的分布策略:复制表,即整张表在每个节点上都有一个完整的拷贝。
CREATE TABLE t2 (id int) DISTRIBUTED REPLICATED;
复制表解决了两个问题:
- UDF 在 segment 上不能访问任何表。由于 MPP 的特性,任何 segment 仅仅包含部分数据,因而在 segment 执行的 UDF 不能访问任何表,否则数据计算错误。
- 避免分布式执行计划:如果一张表的数据在各个 segment 上都有拷贝,那么就可以生成本地连接计划,而避免数据在集群的不同节点间移动。如果用复制表存储数据量比较小的表(譬如数千行),那么性能有明显的提升。 数据量大的表不适合使用复制表模式。
复制表有很多应用场景,譬如 PostGIS 的 spatial_ref_sys (PostGIS 有大量的 UDF 需要访问这张表)和 PLR 中的 plr_modules 都可以采用复制表方式。在支持这个特性之前,Greenplum 只能通过一些小技巧来支持诸如 spatial_ref_sys 之类的表。



