前段时间在虚拟机安装ambari之后一直也没有做测试,今天起来将集群启动发现有些组件启动时遇见一些问题,在这里记录一下。
1. DataNode 无法启动
DataNode启动成功后就死掉了。
1.1 查看DataNode日志寻找原因
首先在DataNode节点进去日志目录 查看日志
[root@hnode3 hdfs]# cd /var/log/hadoop/hdfs
[root@hnode3 hdfs]# less hadoop-hdfs-datanode-hnode3.log
2020-04-27 19:55:55,350 WARN common.Storage (DataStorage.java:loadDataStorage(418)) - Failed to add storage directory [DISK]file:/hadoop/hdfs/data
java.io.IOException: Incompatible clusterIDs in /hadoop/hdfs/data: namenode clusterID = CID-aa0d5fb0-2e14-4c91-90cb-2a27e3c961e6; datanode clusterID = CID-c13d7ddf-1e75-4f0f-9cf3-d3fb50064ee5
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:736)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:294)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:407)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:387)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:551)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1718)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1678)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:390)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:280)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:817)
at java.lang.Thread.run(Thread.java:748)
2020-04-27 19:55:55,352 ERROR datanode.DataNode (BPServiceActor.java:run(829)) - Initialization failed for Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0) service to hnode2/192.168.7.77:8020. Exiting.
java.io.IOException: All specified directories have failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:552)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1718)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1678)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:390)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:280)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:817)
at java.lang.Thread.run(Thread.java:748)
2020-04-27 19:55:55,353 WARN datanode.DataNode (BPServiceActor.java:run(853)) - Ending block pool service for: Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0) service to hnode2/192.168.7.77:8020
2020-04-27 19:55:55,464 INFO datanode.DataNode (BlockPoolManager.java:remove(102)) - Removed Block pool <registering> (Datanode Uuid 2c37038d-0623-4735-9ba4-ac42aff239c0)
2020-04-27 19:55:57,471 WARN datanode.DataNode (DataNode.java:secureMain(2890)) - Exiting Datanode
2020-04-27 19:55:57,560 INFO datanode.DataNode (LogAdapter.java:info(51)) - SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at hnode3/192.168.7.78
************************************************************/
1.2 解决办法
看到日志上说的已经很明确了,DataNode中的clusterID 与NameNode 中的clusterID 不一致,只需手动修改一致即可,这里将DataNode中的clusterID 修改为NameNode中的clusterID
NameNode 的clusterID路径:/hadoop/hdfs/namenode/current/VERSION
DataNode 的clusterID路径:/hadoop/hdfs/data/current/VERSION
先看一下 NameNode中的配置
[root@hnode2 ~]# cat /hadoop/hdfs/namenode/current/VERSION
#Mon Apr 27 17:36:48 CST 2020
namespaceID=1000221201
clusterID=CID-aa0d5fb0-2e14-4c91-90cb-2a27e3c961e6
cTime=1587980208663
storageType=NAME_NODE
blockpoolID=BP-1130886797-192.168.7.77-1587980208663
layoutVersion=-64
修改DataNode中的配置(所有的DataNode都需要修改)
#Tue Mar 31 08:52:25 CST 2020
storageID=DS-d434c580-b494-4af8-a34d-01722614a278
#clusterID=CID-c13d7ddf-1e75-4f0f-9cf3-d3fb50064ee5
clusterID=CID-aa0d5fb0-2e14-4c91-90cb-2a27e3c961e6
cTime=0
datanodeUuid=2c37038d-0623-4735-9ba4-ac42aff239c0
storageType=DATA_NODE
layoutVersion=-57
2. yarn Timeline Service V2.0 无法启动
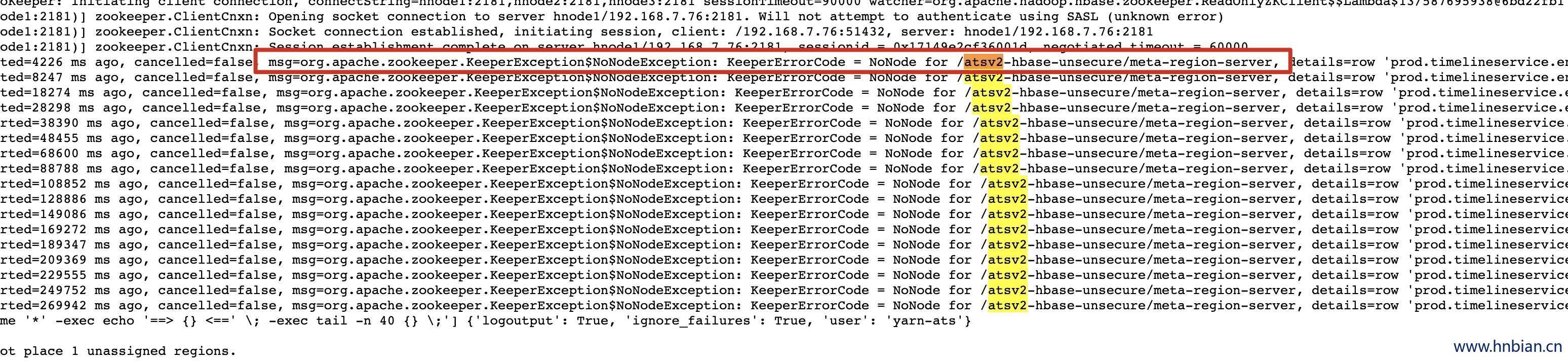
2.1 错误1 zookeeper.KeeperException$NoNodeException
报错信息如下:
org.apache.zookeeper.KeeperException$NoNodeException:
KeeperErrorCode = NoNode for /atsv2-hbase-unsecure/meta-region-server, details=row 'prod.timelineservice.entity' on table 'hbase:meta' at null
2.2 解决办法
需要将YARN中的配置 YARN>CONFIGS>ADVANCED>yarn-hbase-site>zookeeper.znode.parent 的值修改为 HBase 中的配置的值ZooKeeper Znode Parent
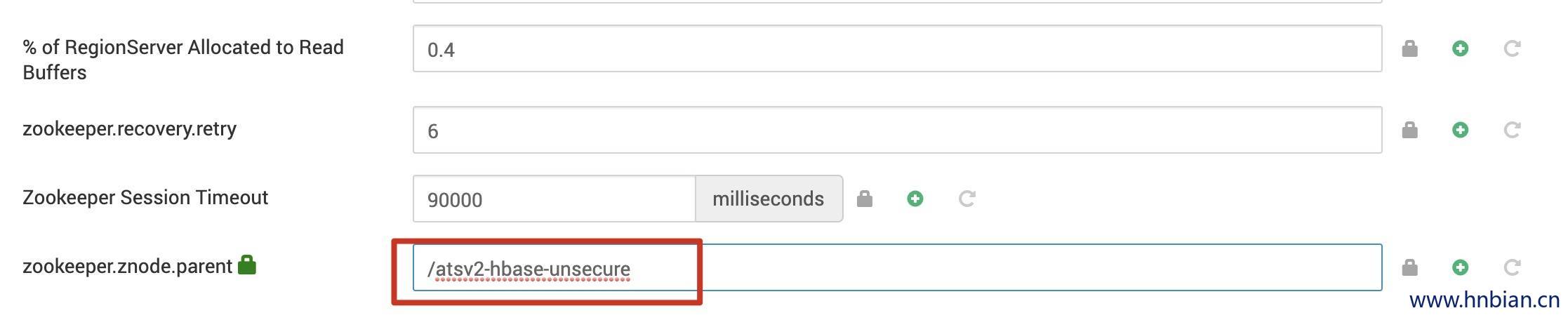

修改之后重启yarn,又报了另一个错误
2.3 错误2 hbase-yarn-ats-regionserver.pid doesn’t exist
Traceback (most recent call last):
File "/var/lib/ambari-agent/cache/stacks/HDP/3.0/services/YARN/package/scripts/timelinereader.py", line 119, in <module>
ApplicationTimelineReader().execute()
File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 355, in execute
self.execute_prefix_function(self.command_name, 'post', env)
File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 382, in execute_prefix_function
method(env)
File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 424, in post_start
raise Fail("Pid file {0} doesn't exist after starting of the component.".format(pid_file))
resource_management.core.exceptions.Fail: Pid file /var/run/hadoop-yarn-hbase/yarn-ats/hbase-yarn-ats-regionserver.pid doesn't exist after starting of the component.
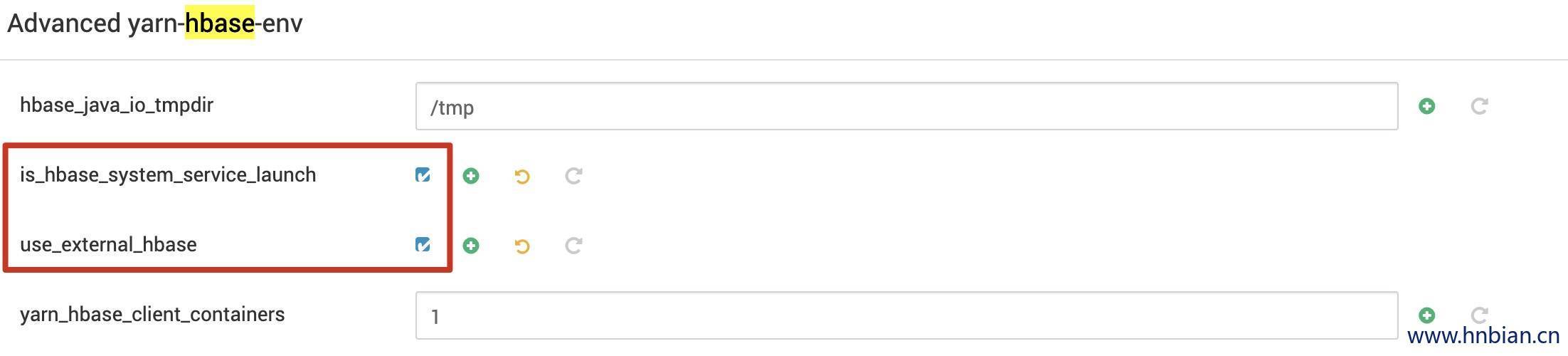
2.4 解决办法
修改yarn配置,将use_external_hbase 与 is_hbase_system_service_launch 勾选