1. 介绍
Flink 支持多种部署方式 如 Local、Standalone、Yarn、K8S 等,但是现在企业中大多数的大数据平台都以 Yarn 作为资源管理器,所以 Flink On Yarn 模式也在企业中用的非常多,下面就介绍一下Flink On Yarn 的使用。
2. Flink on yarn任务提交流程图
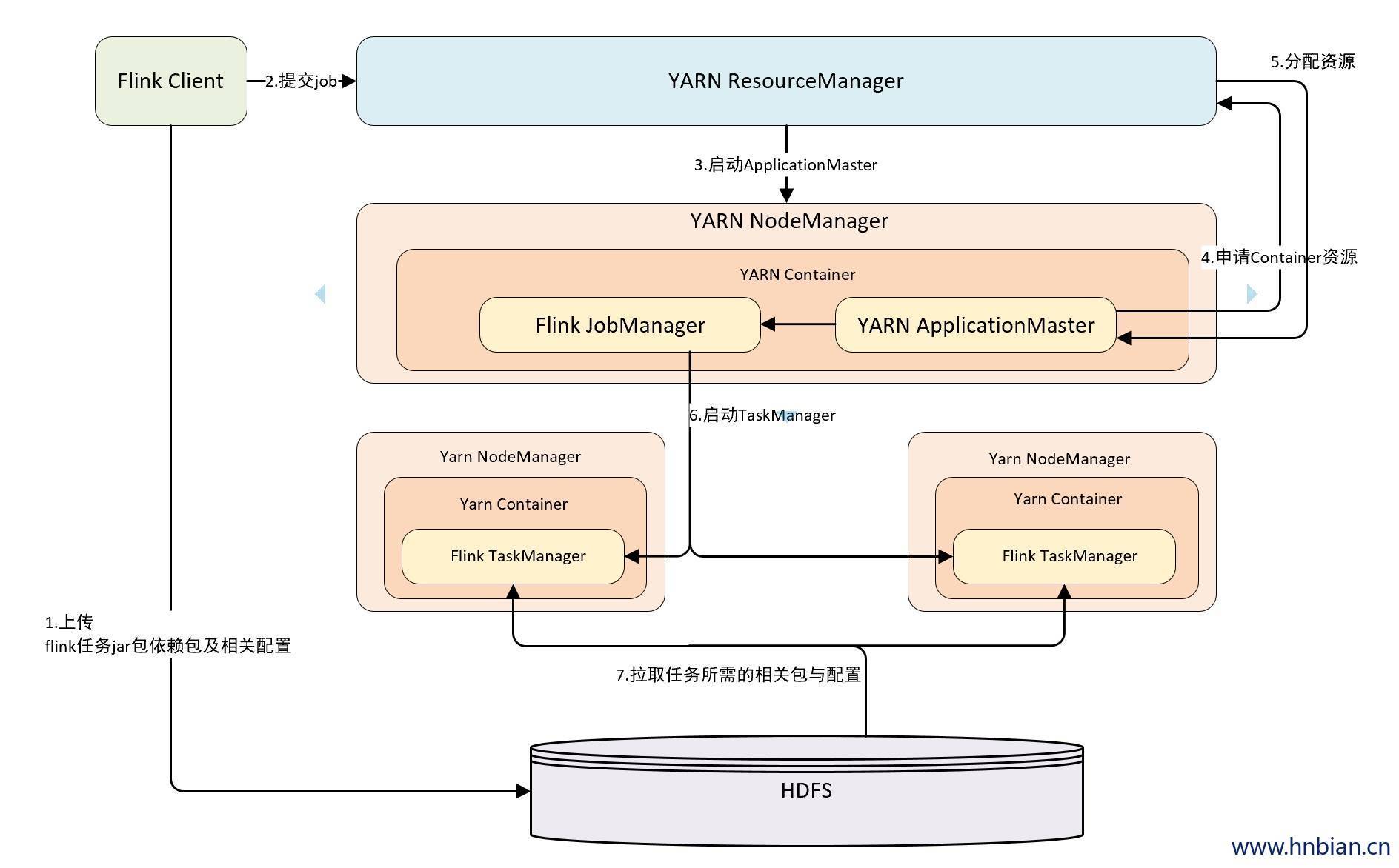
3. 作业提交方式
Flink 作业在yarn上运行有两种提交方式:
- Session 模式
- Per-Job 模式
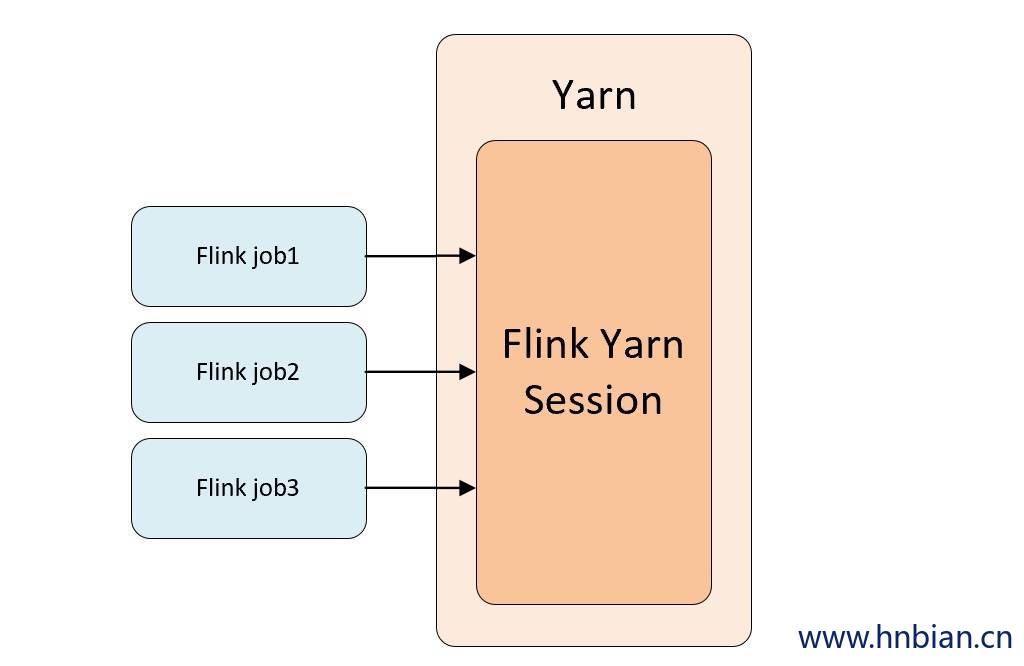
3.1 session 模式
这种方式需要先启动集群,然后再提交作业, 接着会向yarn申请一块空间, 初始化一个session服务常驻在这块空间, 后续提交的任务都运行在这个session上, 如果session资源使用到达上限则接下来的作业无法提交,只能等待到正在运行的某个作业执行完成,释放了部分资源, 接下来的作业才能正常提交,在session模式下多个 Flink jobmanager 会共享Dispatcher 和 YARN ResourceManager。
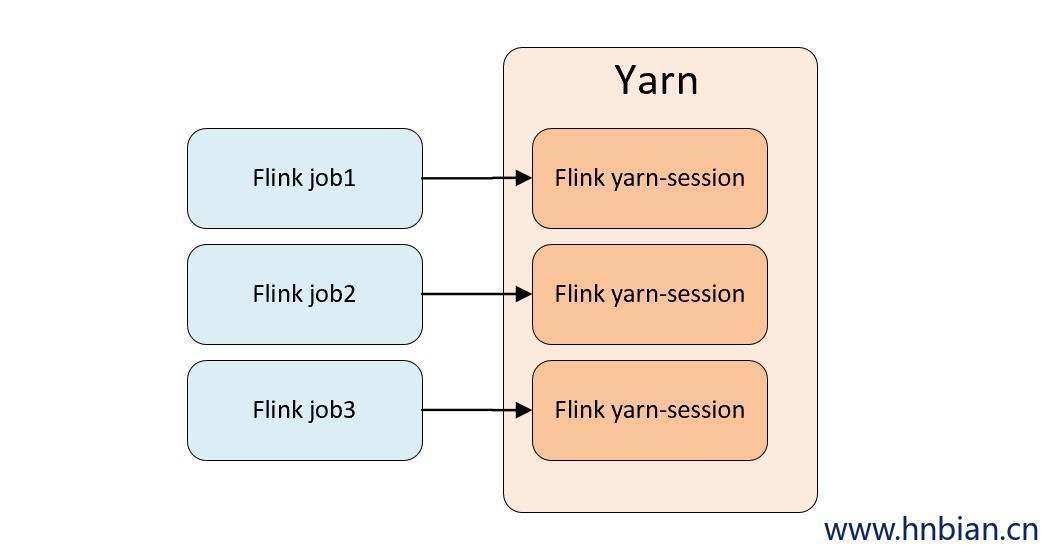
3.2 Per-Job 模式
Per-Job 模式下,每次提交任务都会创建一个新的的 Flink Yarn-session,不同的 Job之间是资源隔离的,不会互相影响,同样Dispatcher和YarnResourceManager也是该任务独享的,任务完成后释放资源。除非是集群资源用尽,否则不会影响新任务的提交。在线上环境一般采用 Per-Job 模式。
4. 提交任务的准备工作
这里Hadoop 的环境是之前装好的,如果 Hadoop 环境没有装好可以先把所需环境装好。并启动好环境。
4.1 配置 hadoop classpath
[root@node2 ~]# vim /etc/profile
#在末尾加上 ps HADOOP_HOME 需要提前配置好
export HADOOP_CLASSPATH=`${HADOOP_HOME}`/bin hadoop classpath
[root@node2 ~]# source /etc/profile
# 打印 hadoop classpath
[root@node2 ~]# echo $HADOOP_CLASSPATH
# 如果出现类似下面内容说明配置成功
/usr/hdp/3.1.0.0-78/hadoop/conf:/usr/hdp/3.1.0.0-78/hadoop/lib/*:/usr/hdp/3.1.0.0-78/hadoop/.//*:/usr/hdp/3.1.0.0-78/hadoop-hdfs/./:/usr/hdp/3.1.0.0-78/hadoop-hdfs/lib/*:/usr/hdp/3.1.0.0-78/hadoop-hdfs/.//*:/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*:/usr/hdp/3.1.0.0-78/hadoop-......4.2 上传 Flink 安装包到服务器上
因为 flink 集群会在 yarn 中创建,这里我们只需要将安装包上传到一台服务器上即可。
# 上传文件并解压(因为之前已经在服务器上安装好 flink 了所以这里就只是演示)
scp flink-1.10.2-bin-scala_2.11.tgz root@node2:/opt
[root@node2 ~]# tar -zxvf flink-1.10.2-bin-scala_2.11.tgz5.使用 yarn-session 模式提交任务
5.1 yarn-session 命令参数说明
# 解压之后进入 binmulu , 使用 -h 查看相关查看参数
[root@node2 bin]# ./yarn-session.sh -h| 参数 | 说明 |
|---|---|
| -at,–applicationType |
为YARN上的应用程序设置自定义应用程序类型 |
| -D <property=value> | 设置属性值,动态属性 |
| -d,–detached | 后台运行 |
| -h,–help | 显示帮助 |
| -id,–applicationId |
指定yarn的任务ID; |
| -j,–jar |
指定 Flink 任务依赖的 jar 包 |
| -jm,–jobManagerMemory |
分配 JobManager 可用内存 (default: MB) |
| -m,–jobmanager |
要连接的 Master JobManager 的地址。这个参数的优先级会高于配置文件中指定的JobManager地址。 |
| -nl,–nodeLabel |
为YARN应用程序指定YARN节点标签; |
| -nm,–name |
YARN上为一个自定义的应用设置一个名字,在 yarnUI 上的名字 |
| -q,–query | 显示yarn中可用的资源 (内存, cpu核数) |
| -qu,–queue |
指定队列 |
| -s,–slots |
指定每一个taskmanager分配多少个slots(处理进程)。 建议设置为每个机器的CPU核数。一般情况下,vcore的数量等于处理的slot(-s)的数量 |
| -t,–ship |
Ship files in the specified directory (t for transfer) |
| -tm,–taskManagerMemory |
TaskManager 可用内存 (default: MB) |
| -yd,–yarndetached | If present, runs the job in detached mode (deprecated; use non-YARN specific option instead) |
| -z,–zookeeperNamespace |
命名空间,用于为高可用性模式创建Zookeeper子路径 |
5.2 启动 yarn-session
[root@node2 bin]$ ./yarn-session.sh -jm 1024m -tm 1024m -d # 如果想后台运行请添加 -d 命令
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.10.2/lib/slf4j-log4j12-1.7.15.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.1.0.0-78/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-12-25 09:48:04,782 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, localhost
2020-12-25 09:48:04,788 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123
2020-12-25 09:48:04,788 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
2020-12-25 09:48:04,789 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.memory.process.size, 1728m
2020-12-25 09:48:04,789 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2020-12-25 09:48:04,789 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1
2020-12-25 09:48:04,790 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.execution.failover-strategy, region
2020-12-25 09:48:05,221 WARN org.apache.flink.runtime.util.HadoopUtils - Could not find Hadoop configuration via any of the supported methods (Flink configuration, environment variables).
2020-12-25 09:48:05,919 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2020-12-25 09:48:06,169 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to hdfs (auth:SIMPLE)
2020-12-25 09:48:06,270 INFO org.apache.flink.runtime.security.modules.JaasModule - Jaas file will be created as /tmp/jaas-4713104554052783620.conf.
2020-12-25 09:48:06,302 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/flink-1.10.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2020-12-25 09:48:06,938 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node1/192.168.0.39:8050
2020-12-25 09:48:07,698 INFO org.apache.hadoop.yarn.client.AHSProxy - Connecting to Application History server at node2/192.168.0.38:10200
2020-12-25 09:48:07,818 INFO org.apache.flink.runtime.clusterframework.TaskExecutorProcessUtils - The derived from fraction jvm overhead memory (172.800mb (181193935 bytes)) is less than its min value 192.000mb (201326592 bytes), min value will be used instead
2020-12-25 09:48:08,236 INFO org.apache.hadoop.conf.Configuration - found resource resource-types.xml at file:/etc/hadoop/3.1.0.0-78/0/resource-types.xml
2020-12-25 09:48:08,304 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-12-25 09:48:08,387 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2020-12-25 09:48:10,050 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
2020-12-25 09:48:16,189 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master 'application_1608705158439_0045' # yarn 上的 ApplicationID
2020-12-25 09:48:17,420 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1608705158439_0045
2020-12-25 09:48:17,420 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated
2020-12-25 09:48:17,422 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2020-12-25 09:48:28,235 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully.
2020-12-25 09:48:28,267 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface node3:37719 of application 'application_1608705158439_0045'.
JobManager Web Interface: 'http://node3:37719' # 通过这个地址可以访问 flibk webUI页面- 查看 yarn 上的 Application

- 查看 Flink webUI http://node3:37719
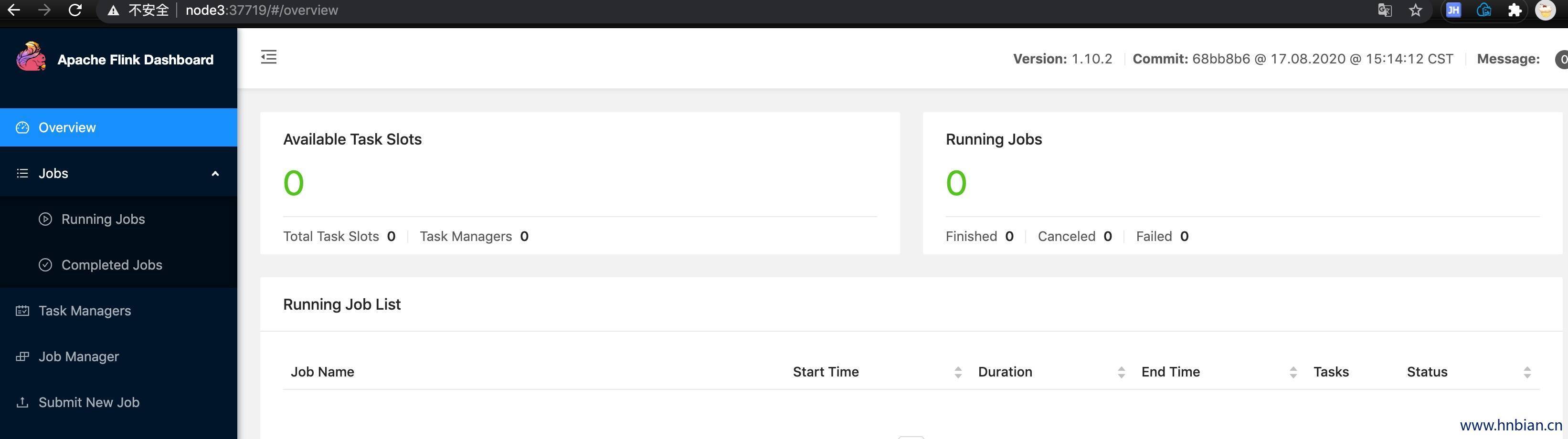
5.3 提交测试任务
- 在 yarn 中启动的 Flink 集群的 ApplicationID 会被保存到 /tmp/.yarn-properties-hdfs 文件中,当向 yarn 中的 flink 集群提交任务时,Flink 程序会先查找该文件内的 ApplicationID.
[hdfs@node2 bin]$ cat /tmp/.yarn-properties-hdfs
#Generated YARN properties file
#Fri Dec 25 09:48:19 CST 2020
dynamicPropertiesString=
applicationID=application_1608705158439_0045- 提交任务
[hdfs@node2 flink-1.10.2]$ bin/flink run ./examples/batch/WordCount.jar # 提交 flink 自带的测试任务
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.10.2/lib/slf4j-log4j12-1.7.15.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.1.0.0-78/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-12-25 10:24:38,016 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-hdfs.
2020-12-25 10:24:38,016 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-hdfs.
2020-12-25 10:24:38,582 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/flink-1.10.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2020-12-25 10:24:38,582 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/flink-1.10.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
2020-12-25 10:24:40,254 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node1/192.168.0.39:8050
2020-12-25 10:24:41,203 INFO org.apache.hadoop.yarn.client.AHSProxy - Connecting to Application History server at node2/192.168.0.38:10200
2020-12-25 10:24:41,231 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-12-25 10:24:41,240 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-12-25 10:24:41,573 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface node2:44910 of application 'application_1608705158439_0048'.
Job has been submitted with JobID c79faee9ef1dbdb1400641c1f65fc825
Program execution finished
Job with JobID c79faee9ef1dbdb1400641c1f65fc825 has finished.
Job Runtime: 26236 ms
Accumulator Results:
- abe323736302b8ad21edede0d34582be (java.util.ArrayList) [170 elements]
# 执行结果
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
(bare,1)
(be,4)
(bear,3)
...- 查看 Flink webUI 中的任务情况
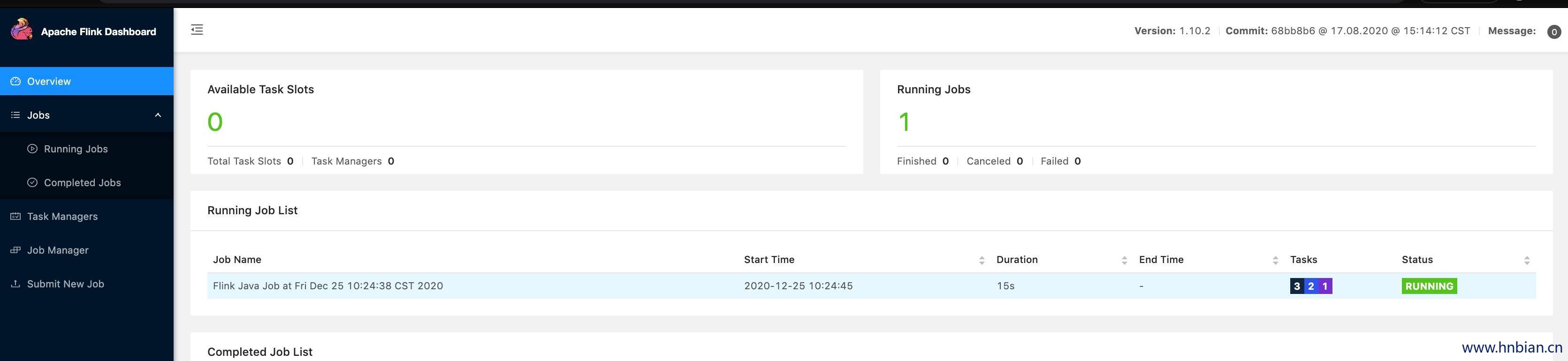
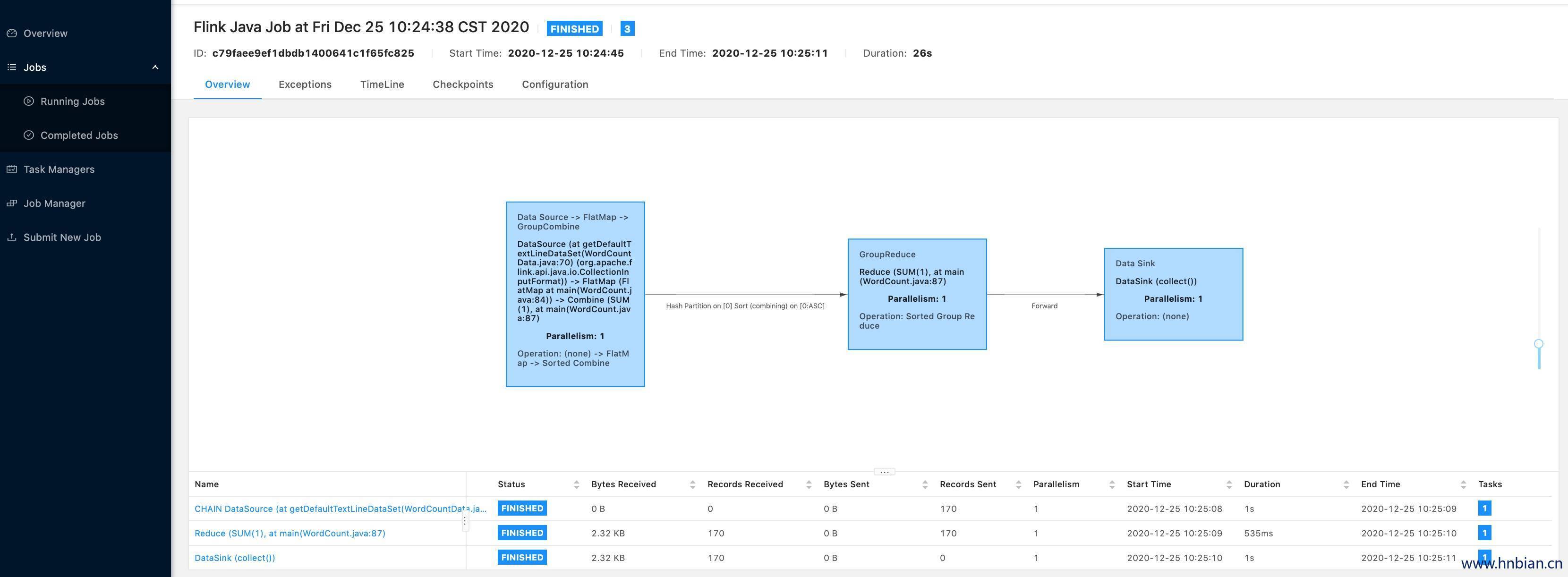
5.4 关闭 yarn 上的 flink 集群
[hdfs@node2 flink-1.10.2]$ yarn application -kill application_1608705158439_0048
20/12/25 10:33:52 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.0.39:8050
20/12/25 10:33:53 INFO client.AHSProxy: Connecting to Application History server at node2/192.168.0.38:10200
Killing application application_1608705158439_0045
20/12/25 10:33:53 INFO impl.YarnClientImpl: Killed application application_1608705158439_00456.使用 Per-Job 模式 提交任务
对于Per-Job模式,提交作业就相对比较简单,不需要提前在yarn 中启动一个 Flink 集群,而是直接提交作业,即可完成Flink作业。
使用 Flink run -m yarn-cluster 命令(创建 Flink 集群并提交任务)
6.1 参数说明
# 查看参数与相关说明
[root@node2 bin]# ./flink run -help| 参数 | 说明 |
|---|---|
| -c,–class |
动态指定 jar包的入口类 |
| -C,–classpath |
Adds a URL to each user code classloader on all nodes in the cluster. The paths must specify a protocol (e.g. file://) and be accessible on all nodes (e.g. by means of a NFS share). You can use this option multiple times for specifying more than one URL. The protocol must be supported by the {@link java.net.URLClassLoader}. |
| -d,–detached | 后台运行 |
| -n,–allowNonRestoredState | 允许跳过无法还原的保存点状态。如果在触发保存点时从程序中删除了一部分运算符,则需要允许此操作。 |
| -p,–parallelism |
动态指定程序的并行度,优先级高于配置文件中的默认值 |
| -py,–python |
带有程序入口点的Python脚本。该相关资源可以用’–pyFiles`选项进行配置。 |
| -pyarch,–pyArchives |
Add python archive files for job. The archive files will be extracted to the working directory of python UDF worker. Currently only zip-format is supported. For each archive file, a target directory be specified. If the target directory name is specified, the archive file will be extracted to a name can directory with the specified name. Otherwise, the archive file will be extracted to a directory with the same name of the archive file. The files uploaded via this option are accessible via relative path. ‘#’ could be used as the separator of the archive file path and the target directory name. Comma (‘,’) could be used as the separator to specify multiple archive files. This option can be used to upload the virtual environment, the data files used in Python UDF (e.g.: –pyArchives file:///tmp/py37.zip,file:///tmp/data. zip#data –pyExecutable py37.zip/py37/bin/python). The data files could be accessed in Python UDF, e.g.: f = open(‘data/data.txt’, ‘r’). |
| -pyexec,–pyExecutable |
Specify the path of the python interpreter used to execute the python UDF worker (e.g.: –pyExecutable /usr/local/bin/python3). The python UDF worker depends on Python 3.5+, Apache Beam (version == 2.15.0), Pip (version >= 7.1.0) and SetupTools (version >= 37.0.0). Please ensure that the specified environment meets the above requirements. |
| -pyfs,–pyFiles |
Attach custom python files for job. These files will be added to the PYTHONPATH of both the local client and the remote python UDF worker. The standard python resource file suffixes such as .py/.egg/.zip or directory are all supported. Comma (‘,’) could be used as the separator to specify multiple files (e.g.: –pyFiles file:///tmp/myresource.zip,hdfs:///$na menode_address/myresource2.zip). |
| -pym,–pyModule |
Python模块与程序的入口点。 此选项必须与–pyFiles 结合使用。 |
| -pyreq,–pyRequirements |
Specify a requirements.txt file which defines the third-party dependencies. These dependencies will be installed and added to the PYTHONPATH of the python UDF worker. A directory which contains the installation packages of these dependencies could be specified optionally. Use ‘#’ as the separator if the optional parameter exists (e.g.: –pyRequirements file:///tmp/requirements.txt#file:///t mp/cached_dir). |
| -s,–fromSavepoint |
job 存储保存点的位置 (如: hdfs:///flink/savepoint-1537). |
| -sae,–shutdownOnAttachedExit | 如果作业以附加模式提交,请在CLI突然终止时(例如,响应用户中断,例如键入Ctrl + C),尽最大努力关闭集群。 |
- Yarn-cluster 模式中的可选参数
| 参数 | 说明 |
|---|---|
| -m,–jobmanager |
动态指定 JobManager 主节点地址 |
| -yid,–yarnapplicationId |
指定yarn的任务ID; |
| -z,–zookeeperNamespace |
命名空间,用于为高可用性模式创建Zookeeper子路径; |
- 默认模式可选参数
| 参数 | 说明 |
|---|---|
| -m,–jobmanager |
要连接的 Master JobManager 的地址。这个参数的优先级会高于配置文件中指定的JobManager地址。 |
| -z,–zookeeperNamespace |
命名空间,用于为高可用性模式创建Zookeeper子路径 |
6.2 提交任务
[hdfs@node2 flink-1.10.2]$ ./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/flink-1.10.2/lib/slf4j-log4j12-1.7.15.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.1.0.0-78/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-12-25 10:49:01,986 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-hdfs.
2020-12-25 10:49:01,986 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-hdfs.
2020-12-25 10:49:02,457 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/flink-1.10.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2020-12-25 10:49:02,457 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/flink-1.10.2/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
2020-12-25 10:49:03,717 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node1/192.168.0.39:8050
2020-12-25 10:49:04,377 INFO org.apache.hadoop.yarn.client.AHSProxy - Connecting to Application History server at node2/192.168.0.38:10200
2020-12-25 10:49:04,423 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2020-12-25 10:49:04,809 INFO org.apache.hadoop.conf.Configuration - found resource resource-types.xml at file:/etc/hadoop/3.1.0.0-78/0/resource-types.xml
2020-12-25 10:49:04,891 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2020-12-25 10:49:05,071 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2020-12-25 10:49:07,172 WARN org.apache.hadoop.hdfs.shortcircuit.DomainSocketFactory - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
2020-12-25 10:49:12,476 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master application_1608705158439_0049
2020-12-25 10:49:12,774 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1608705158439_0049
2020-12-25 10:49:12,775 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated
2020-12-25 10:49:12,777 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2020-12-25 10:49:19,073 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully.
2020-12-25 10:49:19,074 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface node3:35416 of application 'application_1608705158439_0049'.
Job has been submitted with JobID 505a14cbbf0cca7cad029ed90fe048eb
Program execution finished
Job with JobID 505a14cbbf0cca7cad029ed90fe048eb has finished.
Job Runtime: 10932 ms
Accumulator Results:
- 7fbe82214da97e7cbb5a60d0890bdbdb (java.util.ArrayList) [170 elements]
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
(bare,1)
(be,4)
(bear,3)
(bodkin,1)
(bourn,1)
(but,1)- 查看 yarn 中的 application


6.3 其他提交命令
- 连接指定 host 和 port 的 JobManager(已知一个 Flink 集群,并把任务提交到该集群):
bin/flink run -m node1:9999 ./examples/bath/WordCount.jar
- 启动一个新的 yarn-session 并提交任务
bin/flink run -m yarn-cluster -yn 2 ./examples/bath/WordCount.jar
- 注意:bin/flink 可以使用 yarn-session.sh 中的命令,需要添加一个 y 前缀
例如:bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/bath/WordCount.jar



