在Github上面看到一个针对SparkSQL加载Excel数据源的开源组件,拿过来测试了一下spark-excel
1.Spark Excel库
用于使用Apache Spark查询Excel文件的库,用于Spark SQL和DataFrames。
此包允许将Excel电子表格作为Spark DataFrames进行查询。
2.Spark版本要求
该库需要Spark 2.0+
3.重新编译
在github上面该项目代码是用scala2.11版本编译的,我本地测试环境是spark2.4 scala 2.12.8 所以下载源码在服务器上重新编译了一下。如果你使用的是scala2.11版本则可以跳过该步骤。
3.1.安装sbt
因为该项目使用sbt编译的,需要安装sbt 下载好sbt上传到服务器上之后配置环境变量即可。
3.2.下载源码
下载spark-excel源码,并上传服务器。
3.3.修改build.sbt配置
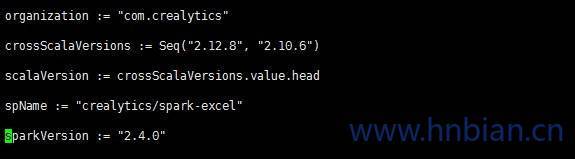
修改Spark 版本到2.4.0
修改scala 版本到2.12.8 如下图
3.4.打包
sbt assembly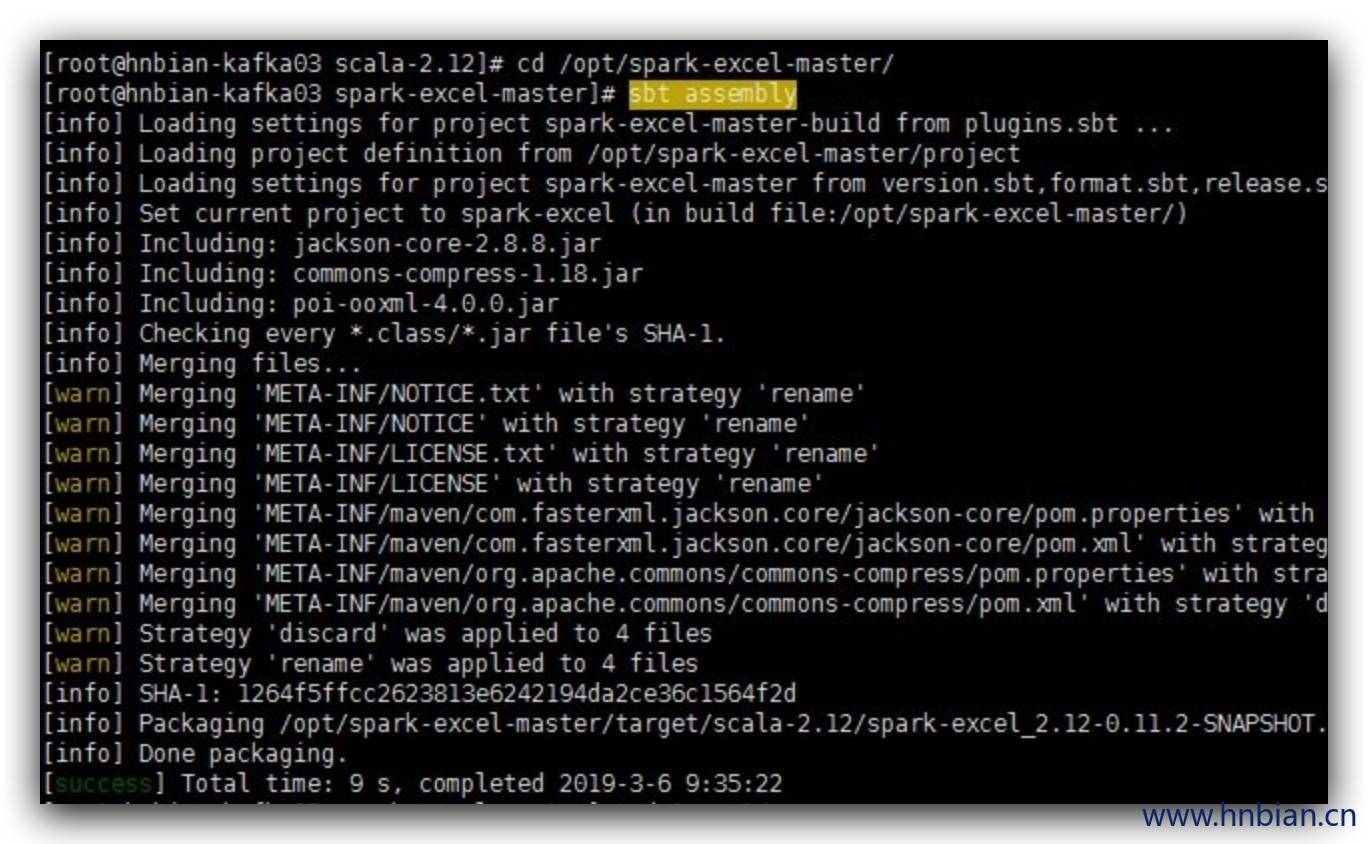
4.添加依赖
在pom.xml中添加依赖 或手动导入刚刚编译的包
<!-- https://mvnrepository.com/artifact/com.norbitltd/spoiwo -->
<dependency>
<groupId>com.norbitltd</groupId>
<artifactId>spoiwo_2.12</artifactId>
<version>1.4.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.monitorjbl/xlsx-streamer -->
<dependency>
<groupId>com.monitorjbl</groupId>
<artifactId>xlsx-streamer</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.crealytics/spark-excel -->
<!--依赖的spark excel 刚刚手动编译导入,如果使用的是scala2.11版本可以直接用此依赖-->
<!--
<dependency>
<groupId>com.crealytics</groupId>
<artifactId>spark-excel_2.11</artifactId>
<version>0.11.1</version>
</dependency>
-->5.读取Excel文件
5.1 代码示例
/**
* @author hnbian 2019/3/5 14:29
*/
object ExcelData {
def main(args: Array[String]): Unit = {
val spark = SparkUtils.getSparkSession("ExcelData", 4)
val sqlContext = spark.sqlContext
val filePath = "D:\\test.xlsx"
//定义数据结构
val schema = StructType(List(
StructField("c1", StringType, nullable = false),
StructField("c2", StringType, nullable = false),
StructField("c3", StringType, nullable = false),
StructField("c4", StringType, nullable = false),
StructField("c5", StringType, nullable = false)))
load(filePath,spark,schema)
}
/**
* 加载Excel数据
* @param filePath 文件路今天
* @param spark SparkSession
* @param schema 数据结构
*/
def load(filePath:String,spark:SparkSession,schema:StructType): Unit ={
val df = spark.read
.format("com.crealytics.spark.excel")
.option("dataAddress", "'Sheet2'!A1:G2") // 可选,设置选择数据区域 例如 A1:E2。
.option("useHeader", "false") // 必须,是否使用表头,false的话自己命名表头(_c0),true则第一行为表头
.option("treatEmptyValuesAsNulls", "true") // 可选, 是否将空的单元格设置为null ,如果不设置为null 遇见空单元格会报错 默认t: true
.option("inferSchema", "true") // 可选, default: false
//.option("addColorColumns", "true") // 可选, default: false
//.option("timestampFormat", "yyyy-mm-dd hh:mm:ss") // 可选, default: yyyy-mm-dd hh:mm:ss[.fffffffff]
//.option("excerptSize", 6) // 可选, default: 10. If set and if schema inferred, number of rows to infer schema from
//.option("workbookPassword", "pass") // 可选, default None. Requires unlimited strength JCE for older JVMs====
//.option("maxRowsInMemory", 20) // 可选, default None. If set, uses a streaming reader which can help with big files====
.schema(schema) // 可选, default: Either inferred schema, or all columns are Strings
.load(filePath)
df.show()
}
}5.2 表格样式
5.2.1 是否使用表头
- excel 中测试数据
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | a1 | a2 | a3 | a4 | a5 |
| 2 | xiaol | xiaom | xiaoh | xiaoy | xiaog |
是否使用表头,不使用的话自己命名表头(_c0), 如果使用则第一行为表头
参数名称: .option(“useHeader”, “false”) //参数为必须
- 使用表头
.option("dataAddress", "'Sheet2'!A1:E2")
.option("useHeader", "true")
df.show()| _c0 | _c1 | _c2 | _c3 | _c4 |
|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 |
| xiaol | xiaom | xiaoh | xiaoy | xiaog |
- 不使用表头
.option("dataAddress", "'Sheet2'!A1:E2")
.option("useHeader", "false")
df.show()| a1 | a2 | a3 | a4 | a5 |
|---|---|---|---|---|
| xiaol | xiaom | xiaoh | xiaoy | xiaog |
5.2.2 选择数据区域
- 选择a1 c1的数据
.option("dataAddress", "'Sheet2'!A1:C1")
.option("useHeader", "false")
df.show()| _c0 | _c1 | _c2 |
|---|---|---|
| a1 | a2 | a3 |
5.2.3 修改空单元格
如果表格中有空数据但不做处理的话会抛出异常
可以使用 .option(“treatEmptyValuesAsNulls”, “true”) // 可选, 默认: true
参数将空的单元格设置为null
- excel 中测试数据
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | a1 | a2 | a3 | a4 | a5 |
| 2 | xiaol | xiaom | xiaoh | xiaog |
如上面表格中D2单元格为空的
设置替换空数值之后表格内容如下:
.option("useHeader", "true")
.option("treatEmptyValuesAsNulls", "true")
df.show()| _c0 | _c1 | _c2 | _c3 | _c4 |
|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 |
| xiaol | xiaom | xiaoh | null | xiaog |
5.2.4 设置schema
设置schema 时需要注意在表格中String 类型数据的单元格不能有为空否则会报空指针。
如果设置范围的列数多余schame的列数那么多余的数据不会读取出来。
参数名称:*.schema(schema) *// 可选
- excel 中测试数据
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | a1 | a2 | a3 | a4 | a5 |
| 2 | xiaol | xiaom | xiaoh | xiaoy | xiaog |
- 设置schema
//定义数据结构
val schema = StructType(List(
StructField("c1", StringType, nullable = false),
StructField("c2", StringType, nullable = false),
StructField("c3", StringType, nullable = false),
StructField("c4", StringType, nullable = false),
StructField("c5", StringType, nullable = false)))
.option("useHeader", "false")
.schema(schema)
df.show()
| c1 | c2 | c3 | c4 | c5 |
|---|---|---|---|---|
| a1 | a2 | a3 | a4 | a5 |
| xiaol | xiaom | xiaoh | xiaoy | xiaog |
6.保存数据到Excel文件中
import hnbian.spark.utils.SparkUtils
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types._
/**
* @author hnbian 2019/3/5 14:29
*/
object ExcelData {
def main(args: Array[String]): Unit = {
val spark = SparkUtils.getSparkSession("ExcelData", 4)
val sqlContext = spark.sqlContext
val filePath = "D:\\test.xlsx"
val fileSavePath = "D:\\testWrite.xlsx"
//定义数据结构
val schema = StructType(List(
StructField("c1", StringType, nullable = false),
StructField("c2", StringType, nullable = false),
StructField("c3", StringType, nullable = false),
StructField("c4", StringType, nullable = false),
StructField("c5", StringType, nullable = false),
StructField("c6", DateType, nullable = false)))
val df = load(filePath,spark,schema)//读取Excel 文件
save(fileSavePath,df) //把刚刚都出来的内容写到另外一个文件中(复制上一个文件)
}
/**
* 将数据保存到Excel文件中
* @param filePath 保存路径
* @param df 数据集
*/
def save(filePath:String,df:DataFrame): Unit ={
df.write
.format("com.crealytics.spark.excel")
.option("dataAddress", "'Sheet'!A1:E2")
.option("useHeader", "true")
//.option("dateFormat", "yy-mmm-d") // Optional, default: yy-m-d h:mm
//.option("timestampFormat", "mm-dd-yyyy hh:mm:ss") // Optional, default: yyyy-mm-dd hh:mm:ss.000
.mode("append") // Optional, default: overwrite.
.save(filePath)
}
/**
* 加载Excel数据
* @param filePath 文件路径
* @param spark SparkSession
* @param schema 数据结构
*/
def load(filePath:String,spark:SparkSession,schema:StructType): DataFrame ={
val df = spark.read
.format("com.crealytics.spark.excel")
.option("dataAddress", "'Sheet2'!A1:E2") // 可选,设置选择数据区域 例如 A1:E2。
.option("useHeader", "false") // 必须,是否使用表头,false的话自己命名表头(_c0),true则第一行为表头
.option("treatEmptyValuesAsNulls", "true") // 可选, 是否将空的单元格设置为null ,如果不设置为null 遇见空单元格会报错 默认t: true
.option("inferSchema", "true") // 可选, default: false
//.option("addColorColumns", "true") // 可选, default: false
//.option("timestampFormat", "yyyy-mm-dd hh:mm:ss") // 可选, default: yyyy-mm-dd hh:mm:ss[.fffffffff]
//.option("excerptSize", 6) // 可选, default: 10. If set and if schema inferred, number of rows to infer schema from
//.option("workbookPassword", "pass") // 可选, default None. Requires unlimited strength JCE for older JVMs====
//.option("maxRowsInMemory", 20) // 可选, default None. If set, uses a streaming reader which can help with big files====
.schema(schema) // 可选, default: Either inferred schema, or all columns are Strings
.load(filePath)
df.show()
df
}
}


