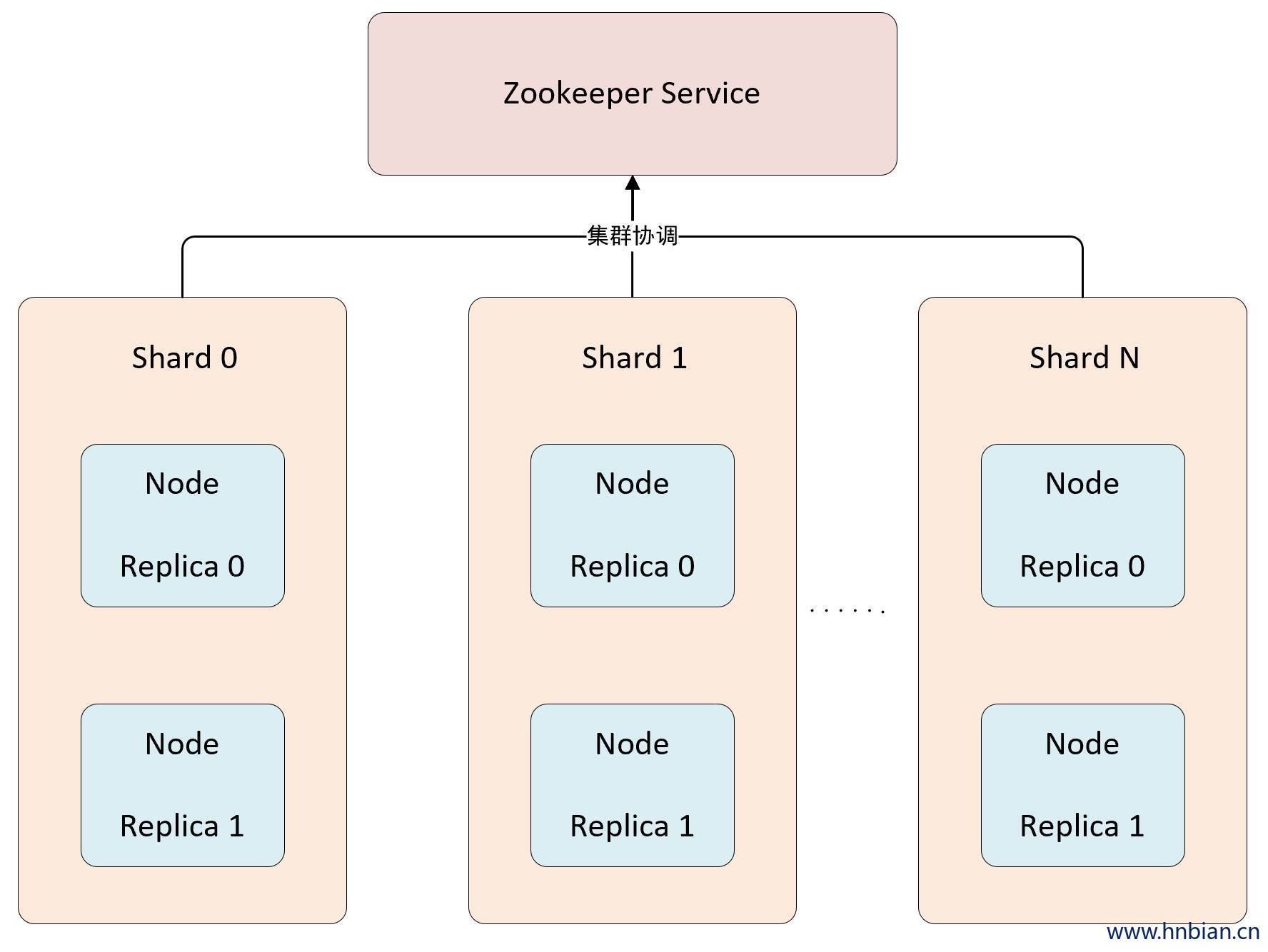
1. 集群结构
ClickHouse 采用了 Multi Master 多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。
多主架构中每个节点对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。
多主架构天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
2. ClickHouse 内部架构
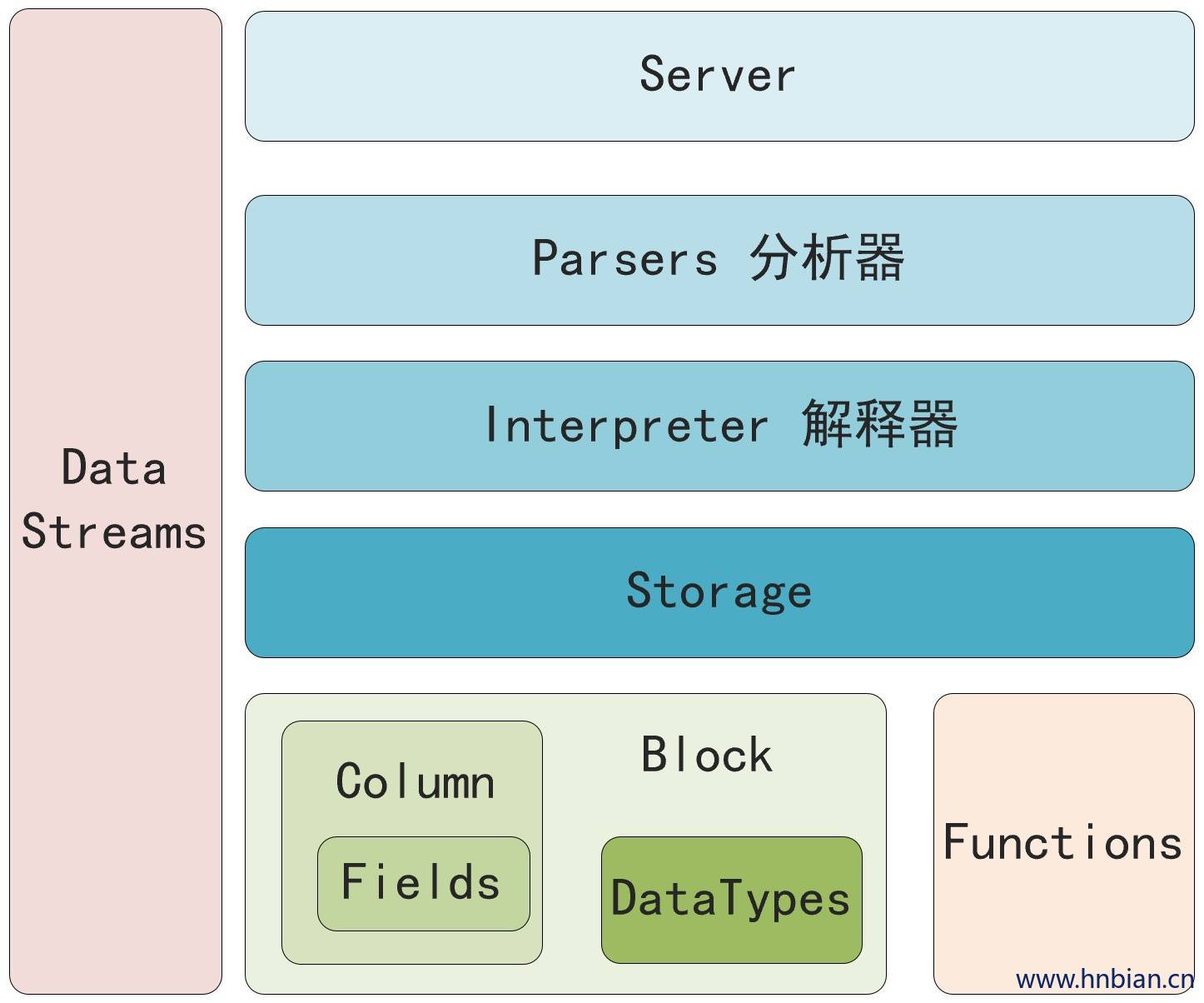
2.1 Field
Field 对象代表一个单值,也就是单列中的一行数据, 在操作预提数值时使用。
Field 对象使用了聚合的设计模式。
Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
2.2 Column
ClickHouse 内存中的一列数据由一个Column对象表示。
Column 对象分为接口和实现两个部分。
在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等,这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等
Column和Field是ClickHouse数据最基础的映射单元。
2.3 DataType
DataType负责数据的序列化和反序列化工作
IDataType接口定义了许多正反序列化的方法,它们成对出现,涵盖了常用的二进制、文本、JSON、XML和CSV等多种格式类型。
DataType虽然负责序列化相关工作,但它并不直接负责数据的读取,而是转由从Column或Field对象获取
2.4 Block
Block对象可以看作数据表的子集。
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。
Block对象的本质是由数据对象(Column)、数据类型(DataType)和列名称组成的三元组。
- Column提供了数据的读取能力
- DataType知道如何正反序列化的能力
Block在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过Block对象就能完成一系列的数据操作。
在具体的实现过程中,Block并没有直接聚合Column和DataType对象,而是通过ColumnWithTypeAndName对象进行间接引用。
2.5 Table
在数据表的底层设计中并没有所谓的Table对象,它直接使用IStorage接口指代数据表。
IStorage接口定义了DDL、read和write方法,它们分别负责数据的定义、查询与写入。
在数据查询时,IStorage负责根据AST查询语句的指示要求,返回指定列的原始数据。后续对数据的进一步加工、计算和过滤,则会统一交由Interpreter解释器对象处理。
对Table发起的一次操作通常都会经历这样的过程,接收AST查询语句,根据AST返回指定列的数据,之后再将数据交由Interpreter做进一步处理。
表引擎是ClickHouse的一个显著特性,不同的表引擎由不同的子类实现,例如IStorageSystemOneBlock(系统表)、StorageMergeTree(合并树表引擎)和StorageTinyLog(日志表引擎)等。
2.6 Parser
- Parser分析器负责创建AST对象。
- Parser分析器可以将一条SQL语句以递归下降的方法解析成AST语法树的形式。
- 分析器有很多种下面例举几种分析器:
- 负责解析DDL查询语句的ParserRenameQuery、ParserDropQuery和ParserAlterQuery解析器,
- 负责解析INSERT语句的ParserInsertQuery解析器,
- 负责SELECT语句的ParserSelectQuery
2.7 Interpreter
Interpreter解释器则负责解释AST,并进一步创建查询的执行管道
Interpreter解释器的作用就像Service服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。
它会解析AST对象
执行“业务逻辑”
返回IBlock对象,以线程的形式建立起一个查询执行管道
Parser、Interpreter与IStorage一起,串联起了整个数据查询的过程。
2.8 Functions
ClickHouse主要提供两类函数——普通函数和聚合函数。
普通函数
由IFunction接口定义,拥有数十种函数实现
普通函数是没有状态的,函数对查询出的每行数据进行操作
在函数具体执行的过程中,采用向量化的方式直接作用于一整列数据
聚合函数
聚合函数由IAggregateFunction接口定义
聚合函数是有状态的
聚合函数的状态支持序列化与反序列化,能够在分布式节点之间进行传输,以实现增量计算



