1. 介绍
Ambari 是一个开源的 Apache 项目,用于部署、监控和管理 Hadoop 集群。Ambari 提供了一个易于使用的 Web UI 和 RESTful API 来简化 Hadoop 集群管理。Ambari 2.7.3 是 Ambari 项目的一个版本。
Flume 是一个分布式、可靠且可用的大数据日志采集、聚合和传输系统。它具有灵活的数据模型,可支持多种数据源和数据存储。Flume 可以将大量的日志数据从不同的来源高效地传输到 Hadoop 分布式文件系统(HDFS)或其他数据存储系统中,以便进行分析和处理。
但是在 Ambari 2.7.3 中,Flume 组件并未默认集成。这意味着在使用 Ambari 2.7.3 部署和管理 Hadoop 集群时,Flume 不会自动可用。要在 Ambari 2.7.3 中使用 Flume,您需要手动集成该组件。
2. 为什么要集成 Flume
- 灵活性:自定义集成 Flume 可以让用户根据自己的需求选择使用 Flume,而不是被迫接受 Ambari 默认提供的组件。这提供了更大的灵活性,用户可以根据项目需求和目标选择所需的组件。
- 定制化:手动集成 Flume 允许用户在整合过程中进行定制,例如,可以选择特定版本的 Flume,定制 Flume 配置文件,以满足特定的业务需求和场景。
- 节省资源:如果您的 Hadoop 集群不需要 Flume 进行日志采集和传输,那么不集成 Flume 可以节省计算资源和存储空间。这样,您可以专注于优化其他重要组件的性能,从而提高整个集群的性能。
- 简化部署和管理:通过手动集成 Flume,您可以更好地了解 Flume 的配置和工作原理。这有助于简化 Hadoop 集群的部署和管理,使您能够更有效地解决遇到的问题。
总之,自定义集成 Flume 组件允许您根据项目需求灵活地部署和管理 Hadoop 集群,提高集群性能并简化集群管理。
3. 下载服务
使用如下github地址,将编译的包,以及将flume添加到ambari-server的web页中的包,克隆到ambari-server所在服务器的一个目录中。
git clone https://github.com/maikoulin/ambari-flume-service.git4. 下载 Flume安装包
去官网下载flume的tar包:https://flume.apache.org/download.html。下个 apache-flume-1.9.0-bin.tar.gz 的tar.gz包,或者直接使用如下命令:
wget https://dlcdn.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz5. 上传 Flume 安装包
将 apache-flume-1.9.0-bin.tar.gz 放到 ambari-flume-service/buildrpm/rpmbuild/SOURCES 这个相对目录下。
6. 编译 ambari-flume-service
ambari-flume-service/buildrpm 目录下执行:
sh buildrpm.sh
# 到此,rpm包编译完成7. 安装 ambari-flume-service
将 flumerpm/ambari-flume-service 相对目录下的Flume 复制到 ambari-server 主机的 /var/lib/ambari-server/resources/stacks/HDP/3.1/services/ 目录下并重启ambari-server:
ambari-server restart
# 到此,ambari的web界面就能识别出来flume了8. 创建 Flume 的本地源
mkdir /var/www/html/flume/
# 创建yum源
createrepo /var/www/html/flume/
# 将上面生成的rpm包拷贝到此
cp ambari-flume-service/buildrpm/rpmbuild/RPMS/noarch/flume-1.9.0-1.el7.noarch.rpm /var/www/html/flume/9. 创建repo
cd /etc/yum.repos.d/
cp centos.repo flume.repo
vim flume.repo
[flume-1.9.0]
name=flume-1.9.0
baseurl=http://hadoop01/flume/
gpgcheck=0
enabled=110. 复制 repo
将 flume.repo复制到需要安装的子节点上
scp flume.repohadoop05:/etc/yum.repos.d/11. 安装 Flume
通过ambariUI安装flume
11.1 点击 add service,勾选flume
11.2 分配客户端
11.3 填写flume agent配置文件
可以在这里填写配置,也可以不填,等安装完成再填写。点击next。
11.4 预览页面
11.5 安装成功
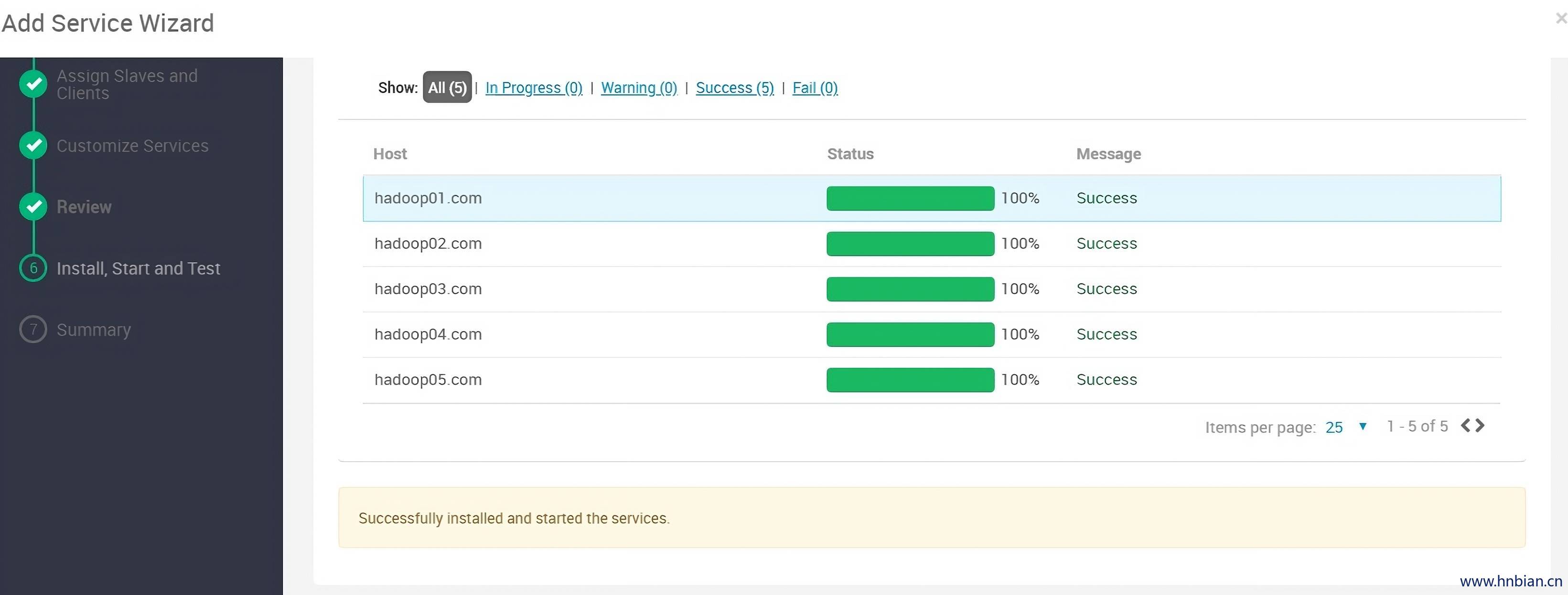
11.6 完成

11.7 填写agent配置文件
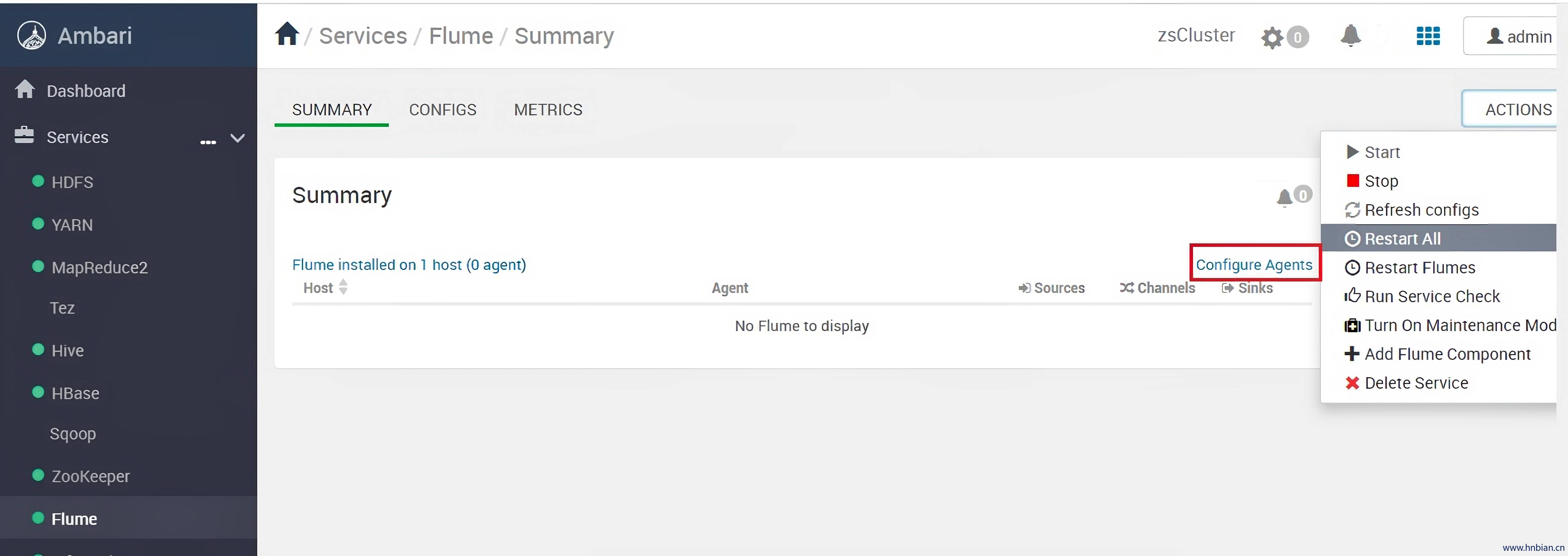
如果刚刚在安装过程过程中没有填写 配置文件,可在此点击 “Configure Agents”,填写配置文件:
12. 测试 1
通过avro方式接受数据,最后通过日志形式输出
# 定义来source、channel和sink
logger.sources = r1
logger.sinks = k1
logger.channels = c1
# 配置source
# 来源类型:Avro
logger.sources.r1.type = Avro
# 绑定的 IP 地址:监听所有 IP 地址
logger.sources.r1.bind = 0.0.0.0
# 监听的端口号:9999
logger.sources.r1.port = 9999
# 配置sink
# sink关联的channel
logger.sinks.k1.channel=c1
# sink 类型:logger (日志接收器)
logger.sinks.k1.type=logger
# 配置 Spillable Memory channel
# channel类型:可溢出内存channel
logger.channels.c1.type=SPILLABLEMEMORY
# 检查点目录
logger.channels.c1.checkpointDir = /data/flume/checkpoint
# 数据目录
logger.channels.c1.dataDirs = /data/flume
logger.sources.r1.channels = c113. 测试 2
通过avro方式接受数据,输出到kafka
# 定义来源、接收器和通道
logger.sources = r1
logger.sinks = k1
logger.channels = c1
# 配置source
# 来源类型:Avro
logger.sources.r1.type = Avro
# 绑定的 IP 地址:监听所有 IP 地址
logger.sources.r1.bind = 0.0.0.0
# 监听的端口号:9999
logger.sources.r1.port = 9999
# 配置sink
# sink 关联的channel
logger.sinks.k1.channel=c1
# 接收器类型:KafkaSink
logger.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
# Kafka Broker 列表
logger.sinks.k1.brokerList=hadoop03:6667,hadoop04:6667,node2:6667
# Kafka topic:testFlume
logger.sinks.k1.topic=testFlume
# 序列化类:StringEncoder
logger.sinks.k1.serializer.class=kafka.serializer.StringEncoder
# 是否在序列化后追加换行符:否
logger.sinks.k1.serializer.appendNewline=false
# 配置 Spillable Memory 通道 (channel)
# 通道类型:可溢出内存通道
logger.channels.c1.type=SPILLABLEMEMORY
# 检查点目录
logger.channels.c1.checkpointDir = /data/flume/checkpoint
# 数据目录
logger.channels.c1.dataDirs = /data/flume
logger.sources.r1.channels = c1保存之后,点击“ACTIONS”>“Restart All”。到此安装完成。
异常解决
Failed to execute command …message: ‘Error: Nothing to do’
Traceback (most recent call last):
File "/var/lib/ambari-agent/cache/stacks/HDP/3.1/services/FLUME/package/scripts/flume_handler.py", line 134, in <module>
FlumeHandler().execute()
File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 352, in execute
method(env)
File "/var/lib/ambari-agent/cache/stacks/HDP/3.1/services/FLUME/package/scripts/flume_handler.py", line 53, in install
self.install_packages(env)
File "/usr/lib/ambari-agent/lib/resource_management/libraries/script/script.py", line 853, in install_packages
retry_count=agent_stack_retry_count)
File "/usr/lib/ambari-agent/lib/resource_management/core/base.py", line 166, in __init__
self.env.run()
File "/usr/lib/ambari-agent/lib/resource_management/core/environment.py", line 160, in run
self.run_action(resource, action)
File "/usr/lib/ambari-agent/lib/resource_management/core/environment.py", line 124, in run_action
provider_action()
File "/usr/lib/ambari-agent/lib/resource_management/core/providers/packaging.py", line 30, in action_install
self._pkg_manager.install_package(package_name, self.__create_context())
File "/usr/lib/ambari-agent/lib/ambari_commons/repo_manager/yum_manager.py", line 219, in install_package
shell.repository_manager_executor(cmd, self.properties, context)
File "/usr/lib/ambari-agent/lib/ambari_commons/shell.py", line 753, in repository_manager_executor
raise RuntimeError(message)
RuntimeError: Failed to execute command '/usr/bin/yum -y install flume', exited with code '1', message: 'Error: Nothing to do'解决办法:
没有配置好 flume 的 yum 源,要把flume.repo复制到需要安装的子节点上,比如:要在 hadoop01、hadoop02 节点安装 flume,则需要把 flume.repo 复制到以上两个节点。
Package flume-1.9.0-1.el7.noarch.rpm is not signed
解决办法:由于 flume 的 rpm 包时在本地编译的,没有对应的签名,将 flume.repo 中的 gpgcheck 设置为 0 即可。 gpgcheck 表示使用gpg 文件来检查软件包的签名。
安装了flume的节点spark-shell启动报错:
hdfs@node2 spark2-client]$ ./bin/spark-shell
Traceback (most recent call last):
File "/bin/hdp-select", line 453, in <module>
listPackages(getPackages("all"))
File "/bin/hdp-select", line 271, in listPackages
os.path.basename(os.path.dirname(os.readlink(linkname))))
OSError: [Errno 22] Invalid argument: '/usr/hdp/current/flume-server'
ls: cannot access /usr/hdp//hadoop/lib: No such file or directory
Exception in thread "main" java.lang.IllegalStateException: hdp.version is not set while running Spark under HDP, please set through HDP_VERSION in spark-env.sh or add a java-opts file in conf with -Dhdp.version=xxx
at org.apache.spark.launcher.Main.main(Main.java:118)解决办法:
将 /usr/hdp/current 下的 flume-server 文件夹复制到 /usr/hdp/3.1.5.0-152 下,然后将 /usr/hdp/current 下的 flume-server 文件夹删除,创建软链接过去
cd /usr/hdp/current
cp -r flume-server ../3.1.5.0-152/
rm -rf flume-server
ln -s /usr/hdp/3.1.5.0-152/flume-server flume-server不显示启动日志
后续使用发现通过 ambari 启动flume,flume的启动日志(/var/log/flume/${agent_name}.out)不显示
解决办法:
在ambari-server所在机器上执行如下命令:
vim /var/lib/ambari-server/resources/stacks/HDP/3.1/services/FLUME/package/scripts/flume.py找到 conf-file 所在位置,添加 -Dflume.root.logger=INFO,console
然后重启 ambari-server,重启flume即可。



