1. OLTP 与 OLAP
1.1 OLTP
- OLTP(on-line transaction processing)联机事务处理
- OLTP 是传统的关系型数据库的主要应用,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。
- 在这样的系统中,单个数据库每秒处理的 Transaction 往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。
- 典型的OLTP系统有电子商务系统、银行、证券等。
1.2 OLAP
- OLAP(On-Line Analytical Processing)联机分析处理
- OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
- OLAP 常使用分区技术、并行技术。
- 分区技术可以使得一些大表的扫描变得很快(只扫描单个分区),而且方便管理。
- 分区结合并行,也可以使得整个表的扫描会变得很快。
1.3 OLTP 与 OLAP的比较
| 比较内容 | 联机业务 | 批处理业务 | |
| 业务特征 | 操作特点 | 日常业务操作,尤其是包含大量前台操作 | 后台操作,例如统计报表,大批量数据加载 |
| 相应速度 | 优先级最高,要求相应速度非常高 | 要求速度高,吞吐量大 | |
| 吞吐量 | 小 | 大 | |
| 并发访问量 | 非常高 | 不高 | |
| 单笔事务消耗资源 | 小 | 大 | |
| SQL 语句类型 | 插入和修改操作为主,DML | 大量查询操作或批量DML操作 | |
| 技术运用 | 索引类型 | B*索引 | Bitmap、Bitmap Join 索引 |
| 索引量 | 适量 | 多 | |
| 访问方式 | 按索引访问 | 全表扫描 | |
| 连接方式 | Nested_loop | Hash Join | |
| BIND 变量 | 使用或强制使用 | 不使用 | |
| 并行技术 | 使用不多 | 大量使用 | |
| 分区技术 | 使用,但目标不同 | 使用,但目标不同 | |
| 物化视图 | 少量使用 | 大量使用 |
2. MPP 简介
2.1 什么是MPP?
MPP (Massively Parallel Processing),即大规模并行处理,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。非共享数据库集群有完全的可伸缩性、高可用、高性能、优秀的性价比、资源共享等优势。
简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
2.2 MPP(大规模并行处理)架构
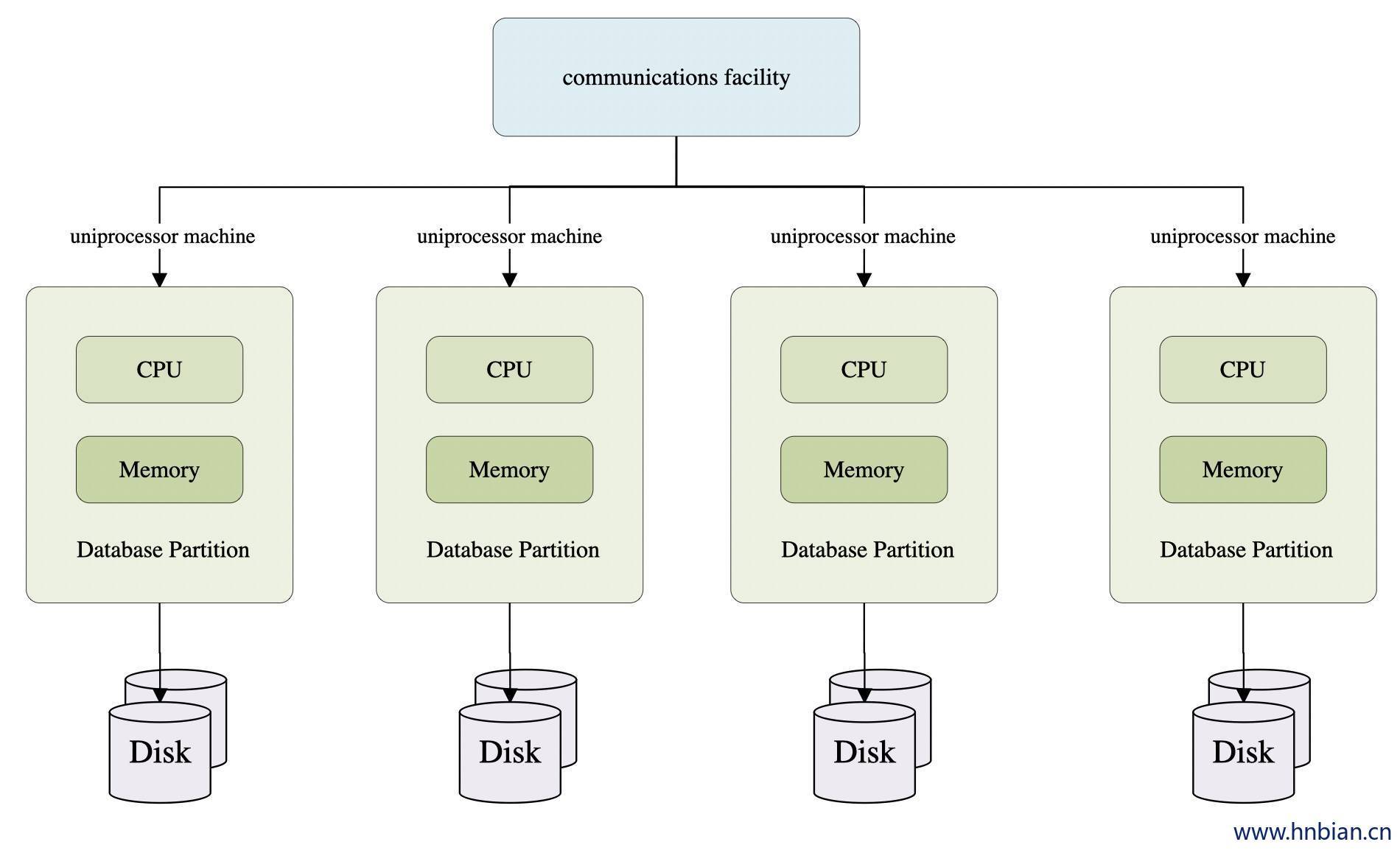
它由多个SMP服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。
2.3 MPP架构特征
任务并行执行
数据分布式存储(本地化)
分布式计算
私有资源
横向扩展
Shared Nothing架构
3. Greenplum 介绍
Greenplum是基于数据库分布式架构的开源大数据平台,采用无共享(no shareing)的MPP架构,具有良好的线性扩展能力,具有高效的并行运算、并行存储等特性。拥有独特的高效的ORCA优化器。兼容SQL语法。适合用于高效PB数据量级的存储、处理和实时分析能力。由于内核是基于PostgreSQL数据库,也支持涵盖OLTP型业务混合负载。同时数据节点和主节点都有自己备份节点。提供数据库的高可用性。
4. Greenplum特性
- 支持海量数据存储和处理
- 高性价比
- 支持Just In Time BI:通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库(ADW),基于动态数据仓库,业务用户能对当前业务数据进行BI实时分析(Just In Time BI)
- 系统易用性
- 支持主流的sql语法,使用起来十分方便,学习成本低
- 扩展性好,支持多语言的自定义函数和自定义类型等
- 提供了大量的维护工具,使用维护起来很方便
- 在internet上有这丰富的postgreSQL资源供用户参考
- 支持线性扩展:采用MPP并行处理架构。在MPP结构中增加节点就可以线性提供系统的存储容量和处理能力
- 较好的并发支持及高可用性支持除了提供硬件级的Raid技术外,还提供数据库层Mirror机制保护,也将每个节点的数据在另外的节点中同步镜像,单个节点的错误不影响整个系统的使用。对于主节点,还提供Master/Stand by机制进行主节点容错,当主节点发生错误时,可以切换到Stand by节点继续服务
- 支持MapReduce计算引擎
- 支持数据库数据内部压缩
5. Greenplum 架构
GPDB是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,每个节点上可以运行多个数据库。Greenplum采用shared nothing架构(MPP),典型的Shared Nothing系统汇集了数据库、内存Cache等存储状态的信息,不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现的。通过将数据分布到多个节点上来实现规模数据的存储,再通过并行查询处理来提高查询性能。每个节点仅查询自己的数据,所得到的结果再经过主节点处理得到最终结果。通过增加节点数目达到系统线性扩展。
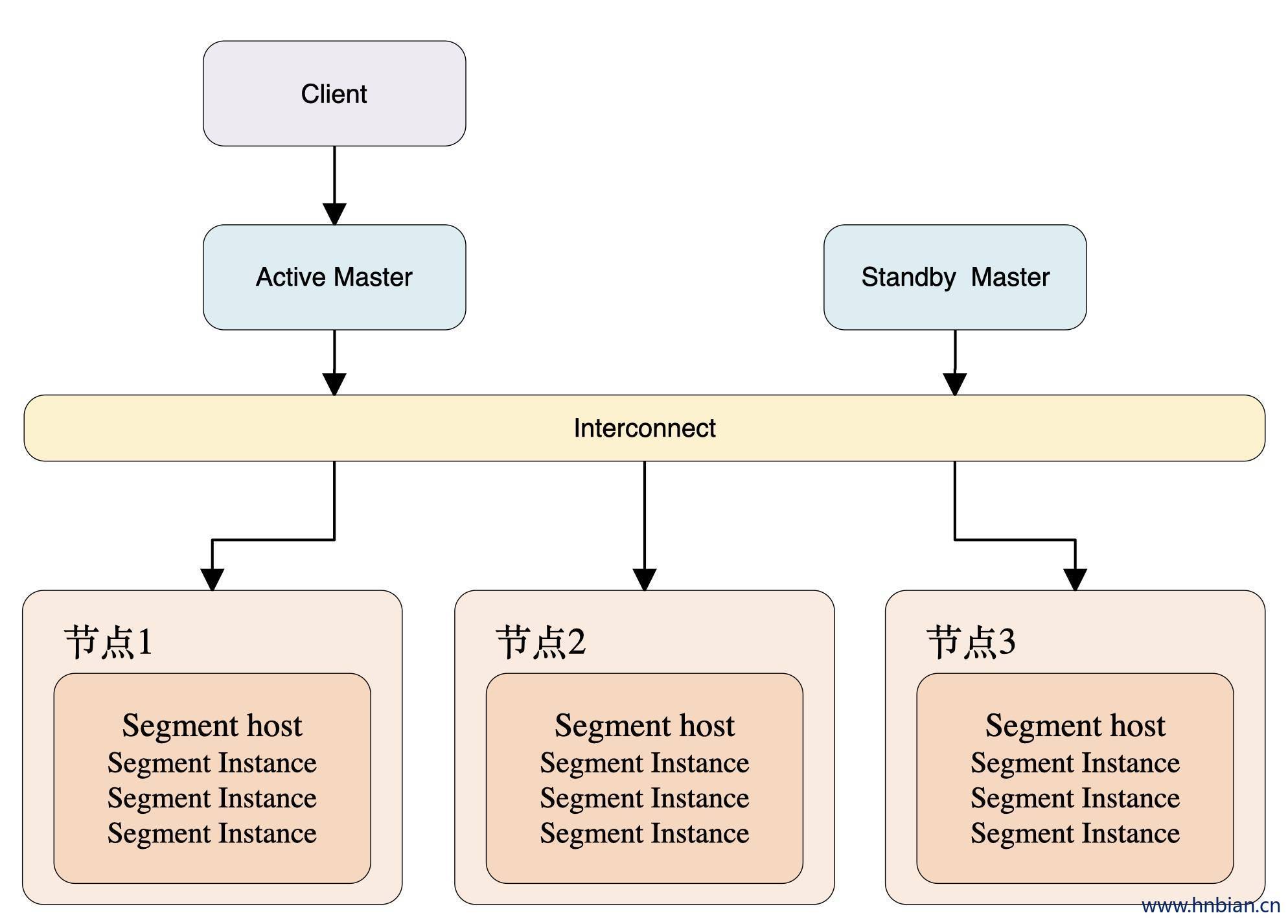
上图为GPDB的基本架构,客户端通过网络连接到gpdb,其中Master 是GP的主节点(客户端的接入点),Segment Host是子节点(连接并提交SQL语句的接口),主节点不存储用户数据,子节点存储数据并负责SQL查询。
主节点负责相应客户端请求并将请求的SQL语句进行转换,转换之后调度后台的子节点进行查询,并将查询结果返回客户端。
5.1 Greenplum Master
- Master 是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上。
- Master 是全局系统目录的所在地。全局系统目录是一组包含了有关Greenplum数据库系统本身的元数据的系统表。Master上不包含任何用户数据,数据只存在于Segment之上。Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。
- Master负责处理连接,通过元数据及统计信息生成执行计划,拆分执行计划,然后分发到segment,segment把自己执行的结果返回给master,master再返回给client。
- Greenplum的最小并行单元不是节点层级,而是在实例层级,在一个节点上有多个Postgresql数据库同时并行工作,可以充分利用到每个节点的所有CPU和IO能力。
Greenplum 功能:
- 访问系统的入口
- 数据库侦听进程(postgres)处理所有用户连接
- 建立查询计划,分发计划
- 协调工作处理过程
- 管理工具
- 系统目录表及元数据(数据字典)
- 不存放任何用户数据
5.1.1 Master高可用
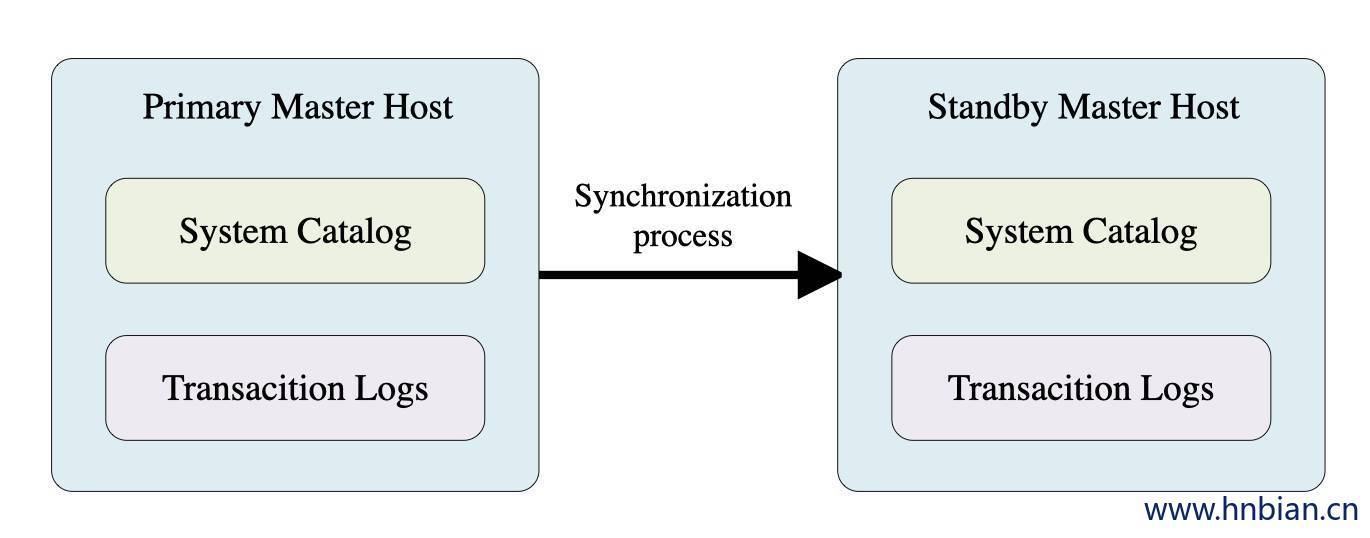
Standby Master 实时与Primary Master节点的catalog和事务日志保持同步,Primary Master损坏时,Standby Master提供 Master服务,当原Primary Master节点恢复后状态将会是Standby。
5.2 Greenplum Segment
5.2.1 Segment 介绍
- Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。
- client 通过Master连接到数据库并且发出一个查询时,在每一个Segment数据库上都会创建一些进程来处理该查询的工作。
- 用户定义的表及其索引会分布在可用的Segment上,每一个Segment都包含数据的不同部分。服务于Segment数据的数据库服务器进程运行在相应的Segment实例之下。
- 一台Segment主机通常运行2至8个Greenplum的Segment,这取决于CPU核数、RAM、存储、网络接口和工作负载。
- Segment主机最好采用相同的配置,这样所有的Segment可以同时开始为一个任务工作并且同时完成它们的工作。木桶原理,整体性能取决于最差的那个segment。
- Segment存贮用户数据的部分,执行query,至少1CPU core、4G内存、单独网络接口。
Segment功能:
- 分段存放数据
- 一个segment host部署多个segment实例
- 实例级别的并行
- 一个系统多个段
- 用户不能直接访问段数据
- 所有对段的访问都要经过master
- 数据库监听进程(postgres)监听来自master 的连接
- 木桶效应
5.2.2 Segment 高可用
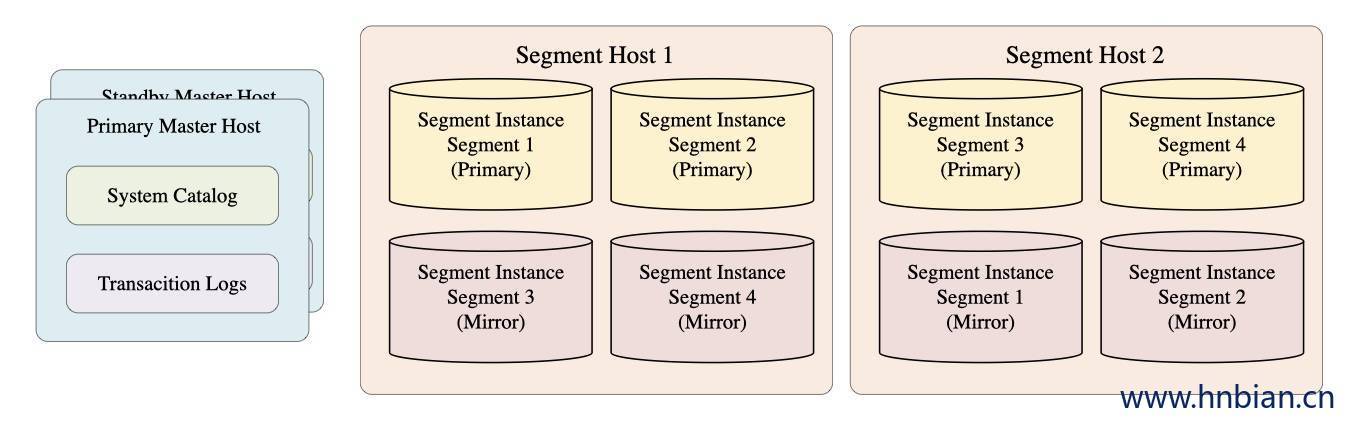
通过基于pg流复制来实现primary与mirror的一致,目前gp仅支持一个primary对应一个mirror。
如果是内存表则通过事务日志去应用。
Append-optimized tables实时同步
Primary Segment 失败后Mirror Segment 接管成为新的Primary Segment,原来的 Primary Segment 恢复后将成为新的Mirror Segment。
5.3 Greenplum Interconnect
- Interconect是Greenplum数据库架构中的网络层。
- Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络基础设施。Greenplum的Interconnect采用了一种标准的以太交换网络。出于性能原因,推荐使用万兆网或者更快的系统。
- 默认情况下,Interconnect使用使用UDPIFC协议在网络上发送消息。Greenplum软件在UDP之上执行包验证。这意味着其可靠性等效于传输控制协议(TCP)且性能和可扩展性要超过TCP。如果Interconnect被改为TCP,Greenplum数据库会有1000个Segment实例的可扩展性限制。对于Interconnect的默认协议UDPIFC则不存在这种限制。
- UDPIFC协议=UDP+流控制(额外的数据验证),可靠性与TCP一致。
- 支持TCP、UDP、UDPIFC
- TCP限制segment数量是1000个
- 节点之间的数据传输
- 基于千兆以太网架构
- 属于系统内部私网配置
- 交换机冗余
- 网卡冗余
6. Greenplum核心组件
Greenplum 数据库包括以下核心组件:
| 组件 | 说明 |
|---|---|
| 解析器 | 主节点收到客户端请求后,执行认证操作。认证成功建立连接后,客户端可以发送查询给数据库。解析器负责对收到的查询SQL字符串进行词法解析、语法解析,并生成语法树。 |
| 优化器 | 优化器对解析器的结果进行处理,从所有可能的查询计划中选择一个最优或者接近最优的计划,生成查询计划。 查询计划描述了如何执行一个查询,通常以树形结构描述。Greenplum最新的优化器叫 ORCA,关于 ORCA,可以从 ACM 论文中获得详细信息。(http://dl.acm.org/citation.cfm?id=2595637&dl=ACM&coll=DL&CFID=569750122&CFTOKEN=89888184) |
| 调度器(QD) | 调度器发送优化后的查询计划给所有数据节点(Segments)上的执行器(QE)。调度器负责任务的执行,包括执行器的创建、销毁、错误处理、任务取消、状态更新等。 |
| 执行器(QE) | 执行器收到调度器发送的查询计划后,开始执行自己负责的那部分计划。典型的操作包括数据扫描、哈希关联、排序、聚集等。 |
| Interconnect | 负责集群中各个节点间的数据传输。 |
| 系统表 | 系统表存储和管理数据库、表、字段的元数据。每个节点上都有相应的拷贝。 |
| 分布式事务 | 主节点上的分布式事务管理器协调数据节点上事务的提交和回滚操作,由两阶段提交(2PC)实现。每个数据节点都有自己的事务日志,负责自己节点上的事务处理。 |
7. Greenplum 和 PostgreSQL 的区别
- Greenplum 在基于 Postgressql 查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
- Greenplum 可以使用追加优化的存储。
- Greenplum 可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。 所有的压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。
- Greenplum 在所有使用列式存储的追加优化表上都提供了压缩。



